I am trying to find out the highest-grossing day per location (date and gross sales amount) in my dataset. I understand that Rank ordering may help here, but im a little stuck on how to go about that. Here is the script so far:
SELECT
DateKey,
SUM(GrossSales),
LocationKey
FROM
dataset
GROUP BY
DateKey, LocationKey
ORDER BY
DateKey, LocationKey
I also tried this script too below, but it only returns the highest grossing day of all locations, not by each and every location:
SELECT
DateKey,
LocationKey,
SUM(GrossSales)
FROM
dataset
GROUP BY
DateKey, LocationKey
HAVING
SUM(GrossSales) = (SELECT MAX(GrossSales)
FROM
(SELECT SUM(GrossSales) AS GrossSales
FROM dataset
GROUP BY Datekey, LocationKey) a )
This is how is how I would like it to look like, as an example:
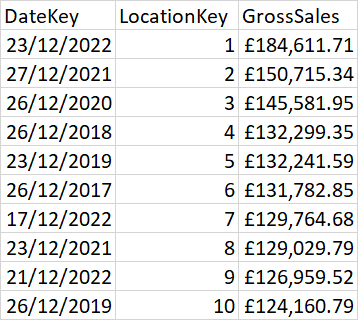
Is there an easy work around here, that I just cant see?
Thank you!
CodePudding user response:
One approach is to perform the initial GROUP BY calculation in a subquery and include a ROW_NUMBER() or RANK() window function to assign sequence numbers. The outer query can then filter for sequence = 1.
Something like:
SELECT
DateKey,
GrossSales,
LocationKey
FROM (
SELECT
DateKey,
SUM(GrossSales) AS GrossSales,
LocationKey,
ROW_NUMBER() OVER(PARTITION BY LocationKey ORDER BY SUM(GrossSales) DESC) AS RN
FROM
dataset
GROUP BY
DateKey, LocationKey
) A
WHERE RN = 1
ORDER BY
LocationKey
Replacing ROW_NUMBER() with RANK() would include all tied values.
See this db<>fiddle for a demo.
CodePudding user response:
Similar to T N's answer above... Full test script
DROP TABLE IF EXISTS #tblTable1;
CREATE TABLE #tblTable1(DateKey date, LocationKey int, GrossSales decimal(28,2));
INSERT INTO #tblTable1(DateKey,LocationKey,GrossSales)
VALUES('2022-12-23', 1, 184611.714)
,('2021-12-27', 2, 150715.34)
,('2020-12-26', 3, 145581.95)
,('2018-12-26', 4, 132299.35)
,('2019-12-23', 5, 132241.59)
,('2017-12-26', 6, 131782.52)
,('2022-12-17', 7, 129764.68)
,('2022-12-29', 7, 9999999.68) --Added
,('2021-12-23', 8, 129029.79)
,('2022-12-21', 9, 126959.52)
,('2019-12-26', 10, 124160.79);
WITH cte_Stuff(LocationKey, DateKey, GrossSales, RowId)
AS (
SELECT TOP 100 PERCENT LocationKey, DateKey, GrossSales, DENSE_RANK() OVER(PARTITION BY LocationKey ORDER BY LocationKey, GrossSales DESC) AS RowId --TOP 100 PERCENTS is Lazy Mans way of trying to enfore sort order within the CTE
FROM #tblTable1 t1
ORDER BY LocationKey, GrossSales DESC
)
SELECT LocationKey, DateKey, GrossSales
FROM cte_Stuff
WHERE RowId = 1