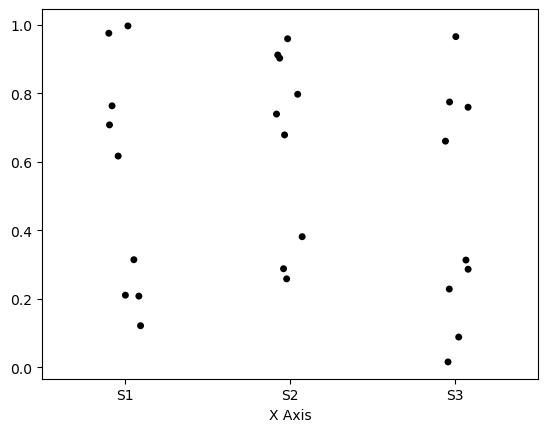
I spent many hours looking for tips how to create categorical plot using Seaborn and Pandas having several Xs to be added on x-axis, but I have not found the solution.
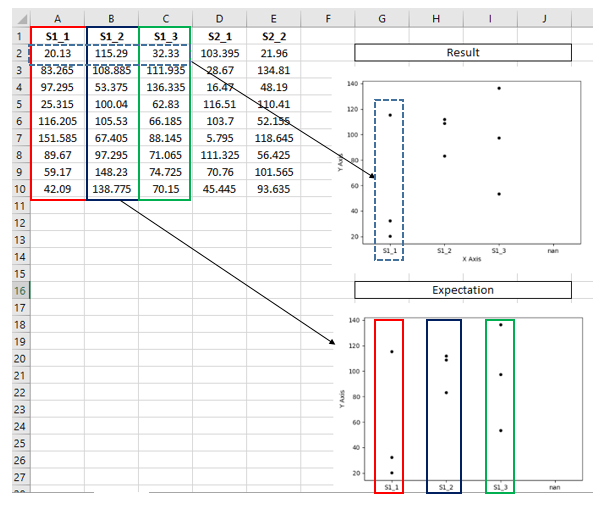
For specified columns from excel (for example: S1_1, S1_2, S1_3) I would like to create one scatterplot with readings - it means for each column header 9 measurements are expected. Please refer to the image to see the data structure in excel. I was unable to find the right function.
I tried with the following code, but this is not what I wanted to achieve.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_excel("panda.xlsx")
dfx = pd.DataFrame({"CHAR": ["S1_1","S1_2","S1_3"]})
sns.stripplot(x=dfx['CHAR'],y=df['S1_1'],color='black')
sns.stripplot(x=dfx['CHAR'],y=df['S1_2'],color='black')
sns.stripplot(x=dfx['CHAR'],y=df['S1_3'],color='black')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.show()
Expected vs obtained plot:
CodePudding user response:
You're overthinking things. You don't need to call stripplot separately for each column. I generated new random data since you didn't share yours in a copy-and-pastable form, but stripplot will basically do what I think you want with a very short invocation.
> print(df)
S1 S2 S3 S4
0 0.314097 0.678525 0.228356 0.770293
1 0.207790 0.739484 0.965662 0.604426
2 0.975562 0.959384 0.088162 0.265529
3 0.616823 0.902795 0.015561 0.662020
4 0.210507 0.287713 0.660347 0.763312
5 0.763505 0.381314 0.759422 0.257578
6 0.707832 0.912063 0.774681 0.534284
7 0.996891 0.258103 0.313047 0.729142
8 0.121308 0.797310 0.286265 0.757299
> sns.stripplot(data=df[["S1", "S2", "S3"]], color='black')
> plt.xlabel("X Axis")