I have 2 tables
xy
Both have different number of rows.
Columns "a" and "b" together act as unique key.
I want the rows in our y dataframe to replace the rows in x dataframe which have common "a" and "b" column values.
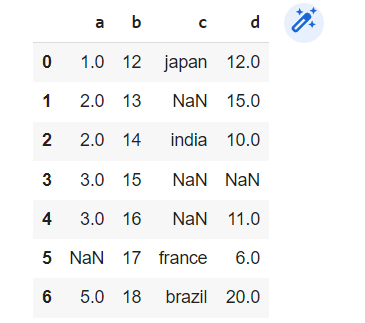
x=pd.DataFrame({"a":[1,2,2,3,3,np.nan,5],
"b":[12,13,14,15,16,17,18],
"c":["japan",np.nan,"india",np.nan,np.nan,"france","brazil"],
"d":[12,15,10,np.nan,11,6,20]})
Result:
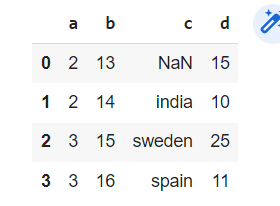
y=pd.DataFrame({"a":[2,2,3,3],
"b":[13,14,15,16],
"c":[np.nan,"india","sweden","spain"],
"d":[15,10,25,11]})
Required output:
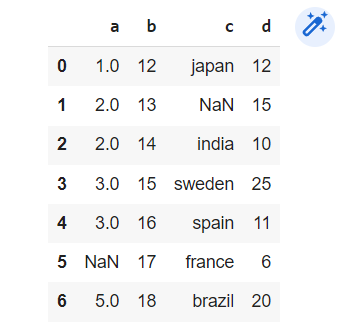
I tried multiple methods like merge(),update() but its not working , please help
CodePudding user response:
Use merge and combine_first:
out = x[['a', 'b']].merge(y, on=['a', 'b'], how='left').combine_first(x)
Output:
a b c d
0 1.0 12 japan 12.0
1 2.0 13 NaN 15.0
2 2.0 14 india 10.0
3 3.0 15 sweden 25.0
4 3.0 16 spain 11.0
5 NaN 17 france 6.0
6 5.0 18 brazil 20.0
CodePudding user response:
If a and b together act as unique keys, you can set them as the index and then use combine_first as @mozway has suggested.
x = x.set_index(["a", "b"])
y = y.set_index(["a", "b"])
out = x.combine_first(y)
c d
a b
1.0 12 japan 12.0
2.0 13 NaN 15.0
14 india 10.0
3.0 15 sweden 25.0
16 spain 11.0
NaN 17 france 6.0
5.0 18 brazil 20.0
You can optionally reset the index after
out.reset_index()
a b c d
0 1.0 12 japan 12.0
1 2.0 13 NaN 15.0
2 2.0 14 india 10.0
3 3.0 15 sweden 25.0
4 3.0 16 spain 11.0
5 NaN 17 france 6.0
6 5.0 18 brazil 20.0
References