Tried the following code to get the headlines and subtitles from the section 
With the information, you can search the section as follows,
import requests
from bs4 import BeautifulSoup
r = requests.get('https://www.theguardian.com/uk/environment')
soup = BeautifulSoup(r.text, 'html.parser')
items = soup.find_all("div", {"class": "fc-item__content"})
for item in items:
print(item.text.strip())
Tip: use .strip() to get the inner text within the A tag.
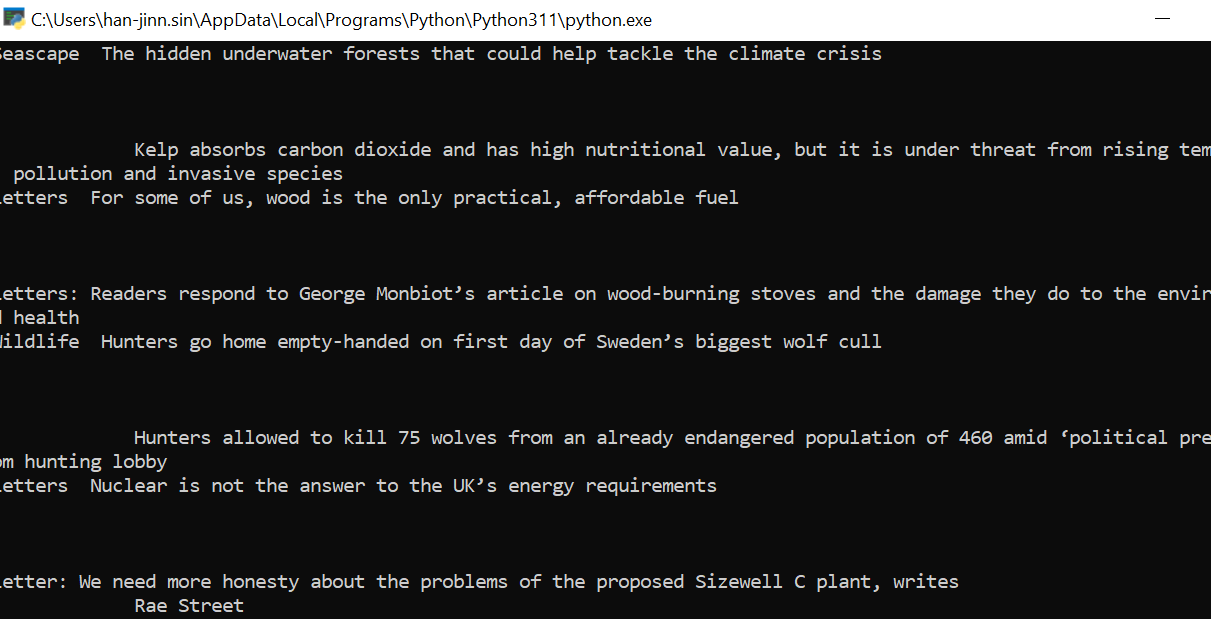
Output gives you:
CodePudding user response:
The following script will extract all of the headlines from the environment/wildlife pages.
An example url from the 3rd Oct 2022 would be:
https://www.theguardian.com/environment/wildlife/2022/oct/03/all
You can modify the script to specify the required start_date and end_date.
Please note, you will have to specify an end_date that is one day beyond the end date you want.
All of the headlines within those dates will be stored in the headlines variable.
I have also introduced a sleep time of 10 seconds between page reads, to avoid being blocked by the website.
Code:
from bs4 import BeautifulSoup
import requests
from datetime import date, timedelta
import pandas as pd
from time import sleep
def get_headings(dt):
p = dt.strftime("%Y-%b-%d").split('-')
r = requests.get(f'https://www.theguardian.com/environment/wildlife/{p[0]}/{p[1].lower()}/{p[2]}/all')
soup = BeautifulSoup(r.text, 'html.parser')
elements = soup.select('div.fc-slice-wrapper')
headings = [h.text for h in elements[0].find_all(class_="js-headline-text")][::2]
return headings
def daterange(start_date, end_date):
for n in range(int((end_date - start_date).days)):
yield start_date timedelta(n)
start_date = date(2022,10,1)
end_date = date(2022,10,4)
headlines = []
for single_date in daterange(start_date, end_date):
headlines.extend(get_headings(single_date))
sleep(10) # sleep 10 seconds between each page to avoid being blocked
for h in headlines:
print(h)
Output:
Gardeners beware: household chemicals banned overseas are still used in Australia
Cop15 is an opportunity to save nature. We can’t afford another decade of failure
Prince Harry wildlife NGO under fire after elephants kill three in Malawi
Country diary: Mysterious birdsong fills the air with sweetness
Tory MPs dismiss critical RSPB campaign as ‘marketing strategy’
Australia announces plan to halt extinction crisis and save 110 species
Sixty endangered greater gliders found in Victorian forests tagged for logging
Wales unveils plans to triple rate of peatland restoration
Europe and UK hit by ‘unprecedented’ number of bird flu cases this summer