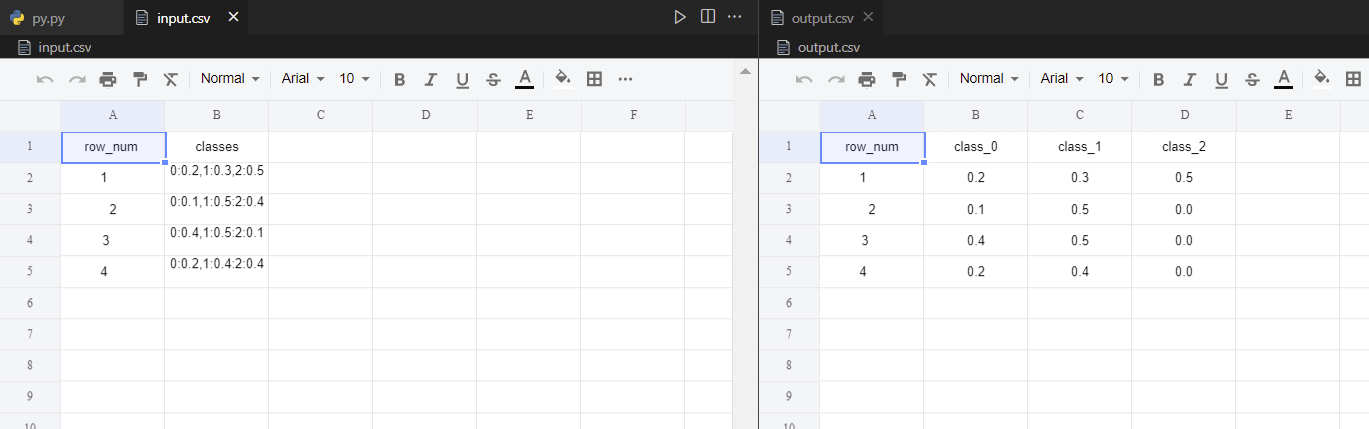
I have csv file which contains data in below format
| row_num | classes |
|---|---|
| 1 | 0:0.2,1:0.3,2:0.5 |
| 2 | 0:0.1,1:0.5:2:0.4 |
| 3 | 0:0.4,1:0.5:2:0.1 |
| 4 | 0:0.2,1:0.4:2:0.4 |
I want it to be converted as follows:
| row_num | class_0 | class_1 | class_2 |
|---|---|---|---|
| 1 | 0.2 | 0.3 | 0.5 |
| 2 | 0.1 | 0.5 | 0.4 |
| 3 | 0.4 | 0.5 | 0.1 |
| 4 | 0.2 | 0.4 | 0.4 |
Please help me with this transformation using pyspark.
CodePudding user response:
TLDR-
df.select("row", F.explode(F.split("classes",",")).alias("keyValue")).select("row", F.split("keyValue",":")[0].alias("key"), F.split("keyValue",":")[1].alias("value")).groupBy("row").pivot("key").agg(F.first("value")).show()
Output

Essentially,
Split the column to form an array
df.select("row", F.split("classes",",").alias("as_array")).show(truncate=False)

- Explode it to form rows for each element in the array corresponding to column "row_num"
df.select("row", F.explode("as_array").alias("asKeyValue"))
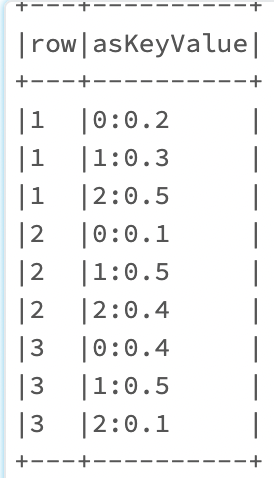
- Split key and values as separate columns
df.select("row", F.split("asKeyValue",":")[0].alias("key"), F.split("asKeyValue",":")[1].alias("value"))
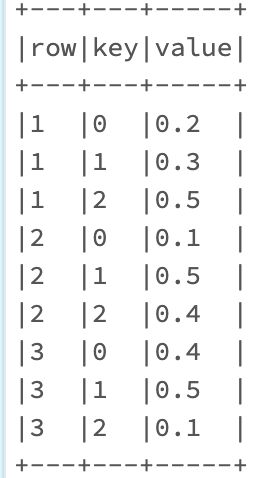
- Pivot based on Row Number
CodePudding user response:
Python code that should do the conversion you described But Not with Pyspark :
import csv
# Open the input CSV file
with open('input.csv', 'r') as input_file:
# Create a CSV reader object
reader = csv.reader(input_file)
# Skip the header row
next(reader)
# Open the output CSV file
with open('output.csv', 'w', newline='') as output_file:
# Create a CSV writer object
writer = csv.writer(output_file)
# Write the header row
writer.writerow(['row_num', 'class_0', 'class_1', 'class_2'])
# Loop over the rows in the input file
for row in reader:
# Split the 'classes' field on ','
class_values = row[1].split(',')
# Convert the values to a dictionary
class_dict = {int(x.split(':')[0]): float(x.split(':')[1]) for x in class_values}
# Write the row to the output file
writer.writerow([row[0], class_dict.get(0, 0.0), class_dict.get(1, 0.0), class_dict.get(2, 0.0)])
This code will read the input CSV file, skip the header row, and then loop over the remaining rows. For each row, it will split the classes field on ',', convert the values to a dictionary, and then write a new row to the output CSV file with the row_num field and the values from the dictionary under the class_0, class_1, and class_2 columns.