I got this function that parses a string with special characters escaped by a backslash.
parseEscapedString :: Parser String
parseEscapedString =
char '\''
*> many'
( notChar '\'' >>= \case
'\\' -> anyChar
c -> pure c
)
<* char '\''
I'm using attoparsec, specifically Data.Attoparsec.ByteString.Char8
While this function works as expected it uses insane amounts of memory when parsing large amounts of strings.
I have a file that's 850Mb in size and contains stuff that I want to parse, part of which are these strings.
But when I try to parse this file the program needs around 10Gb of memory to successfully complete (-O2).
When compiled with -prof and run with RTS -hc the heap usage statistics show that the main parsing function slightly increases memory usage which is to be expected for allocating the parsed structures, however, the biggest memory usage comes from the function parseEscapedString and is absolutely enormous.
Is this a memory leak from attoparsec or bytestring or did I screw something up?
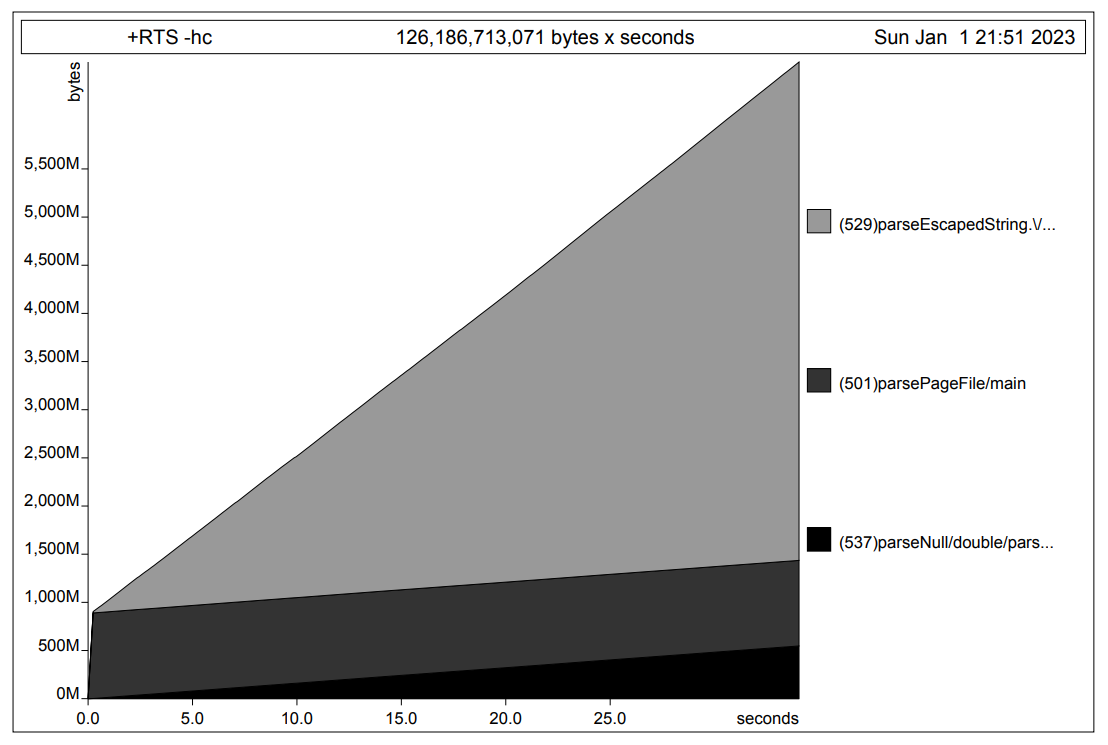 (This was saved 40s after running, but when compiled with
(This was saved 40s after running, but when compiled with -prof the program is rather slow and runs about 5min before getting killed because of insufficient memory (using around 20GB) which leads to the statistics not being saved but I don't think there's any difference to the first 40 seconds.
CodePudding user response:
It may just be the storage of the Strings themselves.
Recall that a GHC String is a linked list representation. It turns out that it requires 24 bytes per character "node" (consisting of three 64-bit quads per node: the info pointer for the : constructor, a pointer to the Char, and a pointer to the next node). If, say, 50% of your 850MB file consists of strings, parsing it will require 0.50*850*24=10200 megabytes of resident string storage. This is independent of the details of your parser. You would see the same issue with a parser like:
everything :: Parser String
everything = many' anyChar
The simplest fix is to parse into a strict Text or ByteString representation. Since you're only handling Char8 strings, a ByteString representation makes sense. The following Parser ought to work. You will still need resident storage equal to the total ByteString needs of your strings, but it should be 24 times less storage than the plain String representation:
import qualified Data.ByteString.Char8 as C
parseEscapedString :: Parser C.ByteString
parseEscapedString = fmap C.pack $
char '\''
*> many'
( notChar '\'' >>= \case
'\\' -> anyChar
c -> pure c
)
<* char '\''