I'd like to fit a neural network using brulee but despite the several changes in the model parameters (changes in all the parameters), I always have the almost same value in the predictions. In my case:
# Open the data set
data_train_sub <- read.csv("https://raw.githubusercontent.com/Leprechault/trash/main/cc_test_ds.csv")
# Model parameters
hidden_units <-c(4)
epochs <-c(50)
dropout <-c(0.01)
learn_rate <- c(0.01)
activation <- c("relu")
penalty <- c(0.01)
validation <-c(0.80)
# Training data set
data_train <- data_train_sub[1:1250,]
# Validation data set
data_test <- data_train_sub[1251:1500,]
# Model fitting
fit <- brulee_mlp(x = as.matrix(data_train[, 2:ncol(data_train)]),
y = data_train$cc,
hidden_units = hidden_units,
epochs = epochs, dropout = dropout, learn_rate = learn_rate, activation = activation,
penalty = penalty,validation=validation)
#Plot
predict(fit, data_test) %>%
bind_cols(data_test) %>%
ggplot(aes(x = .pred, y = cc))
geom_abline(col = "green")
geom_point(alpha = .3)
lims(x = c(0, 1.0), y = c(0, 1.0))
coord_fixed(ratio = 1)
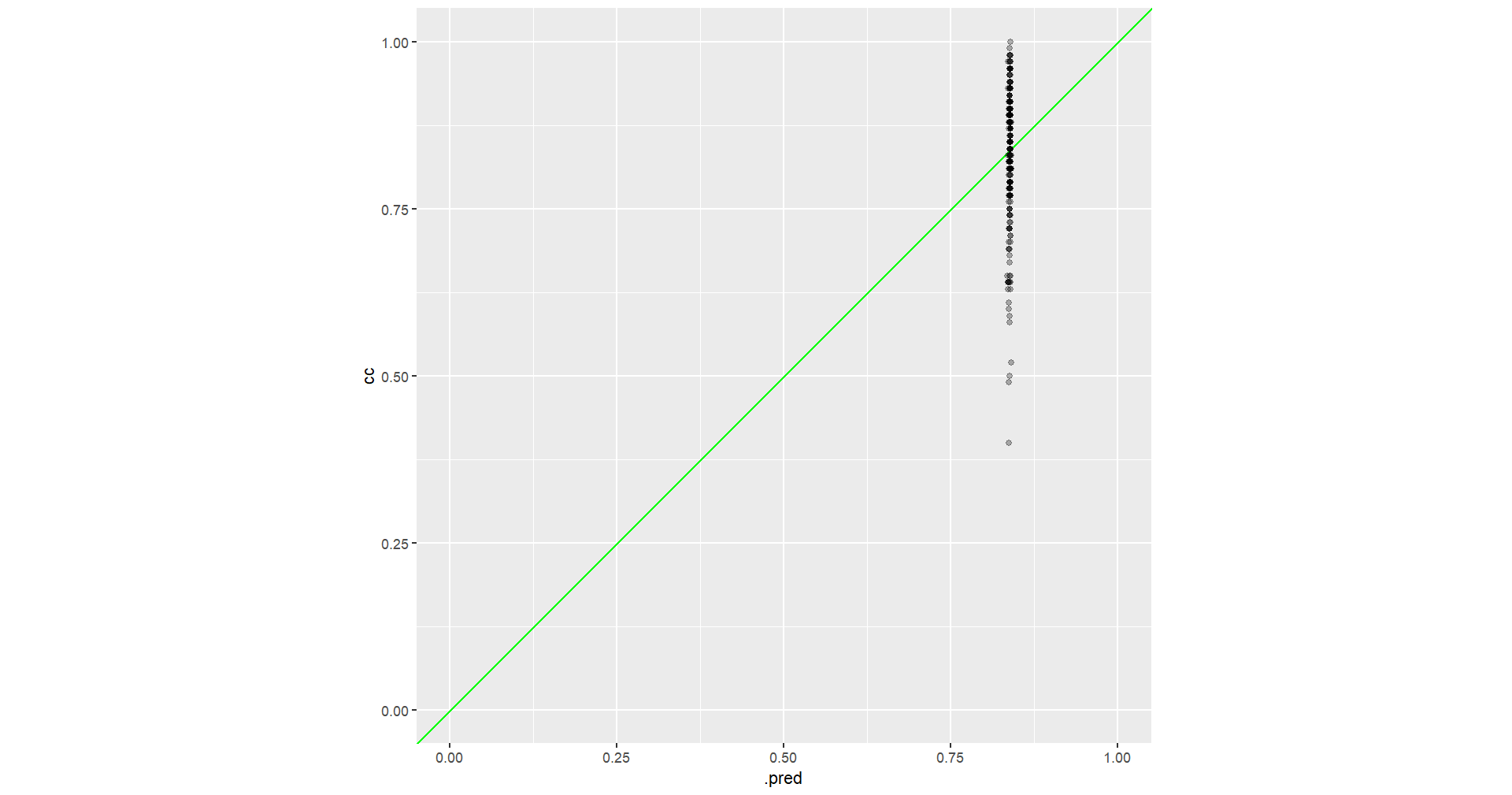
This sounds strange to me. I would appreciate any help.
Thanks in advance!
CodePudding user response:
The main issues were the outliers mentioned above and that you needed to standardize your predictors to be on the same scale.
Although the model doesn't fit great, here is a modified version with more complexity (but gives different predicted values). I also added PCA which helps a small amount (but you could leave that step out of the recipe).
library(tidymodels)
library(brulee)
tidymodels_prefer()
theme_set(theme_bw())
options(pillar.advice = FALSE, pillar.min_title_chars = Inf)
data_train_sub <- read.csv("https://raw.githubusercontent.com/Leprechault/trash/main/cc_test_ds.csv")
# Model parameters
hidden_units <-c(50) # more hidden units
epochs <-c(500) # more iterations
dropout <-c(0) # since we are using penalization, no dropout
learn_rate <- c(0.01)
activation <- c("relu")
penalty <- c(0.01)
validation <-c(0.20) # hold out 20%
# Training data set
data_train <- data_train_sub[1:1250,]
# There are two extreme outliers:
data_train_2 <- data_train %>% slice(-c(64, 162))
# Validation data set
data_test <- data_train_sub[1251:1500,]
rec <-
recipe(cc ~ ., data = data_train_2) %>%
step_normalize(all_predictors()) %>%
step_pca(all_predictors())
set.seed(1)
# Model fitting
fit <- brulee_mlp(rec, data = data_train_2,
hidden_units = hidden_units,
epochs = epochs, dropout = dropout, learn_rate = learn_rate, activation = activation,
penalty = penalty,validation=validation)
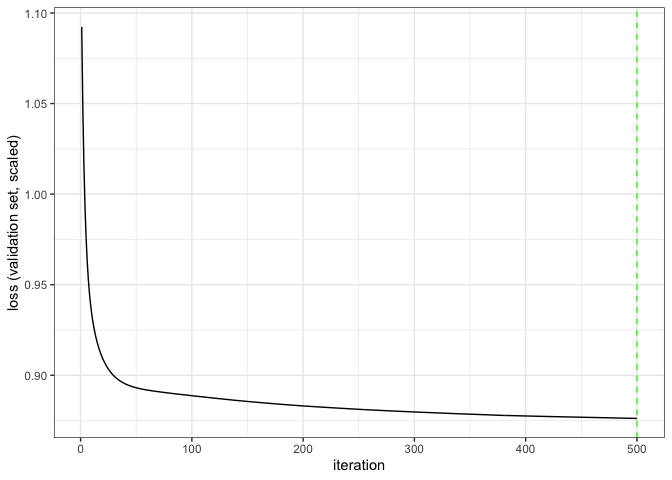
# check convergence
autoplot(fit)
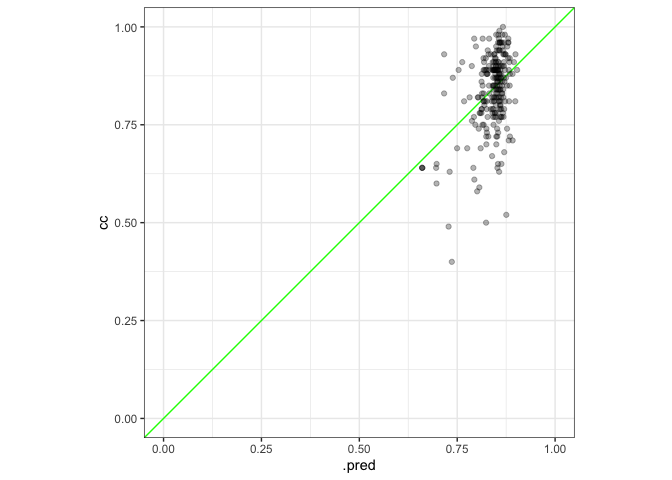
#Plot
predict(fit, data_test) %>%
bind_cols(data_test) %>%
ggplot(aes(x = .pred, y = cc))
geom_abline(col = "green")
geom_point(alpha = .3)
lims(x = c(0, 1.0), y = c(0, 1.0))
coord_fixed(ratio = 1)
Created on 2023-01-04 by the reprex package (v2.0.1)