I went over the 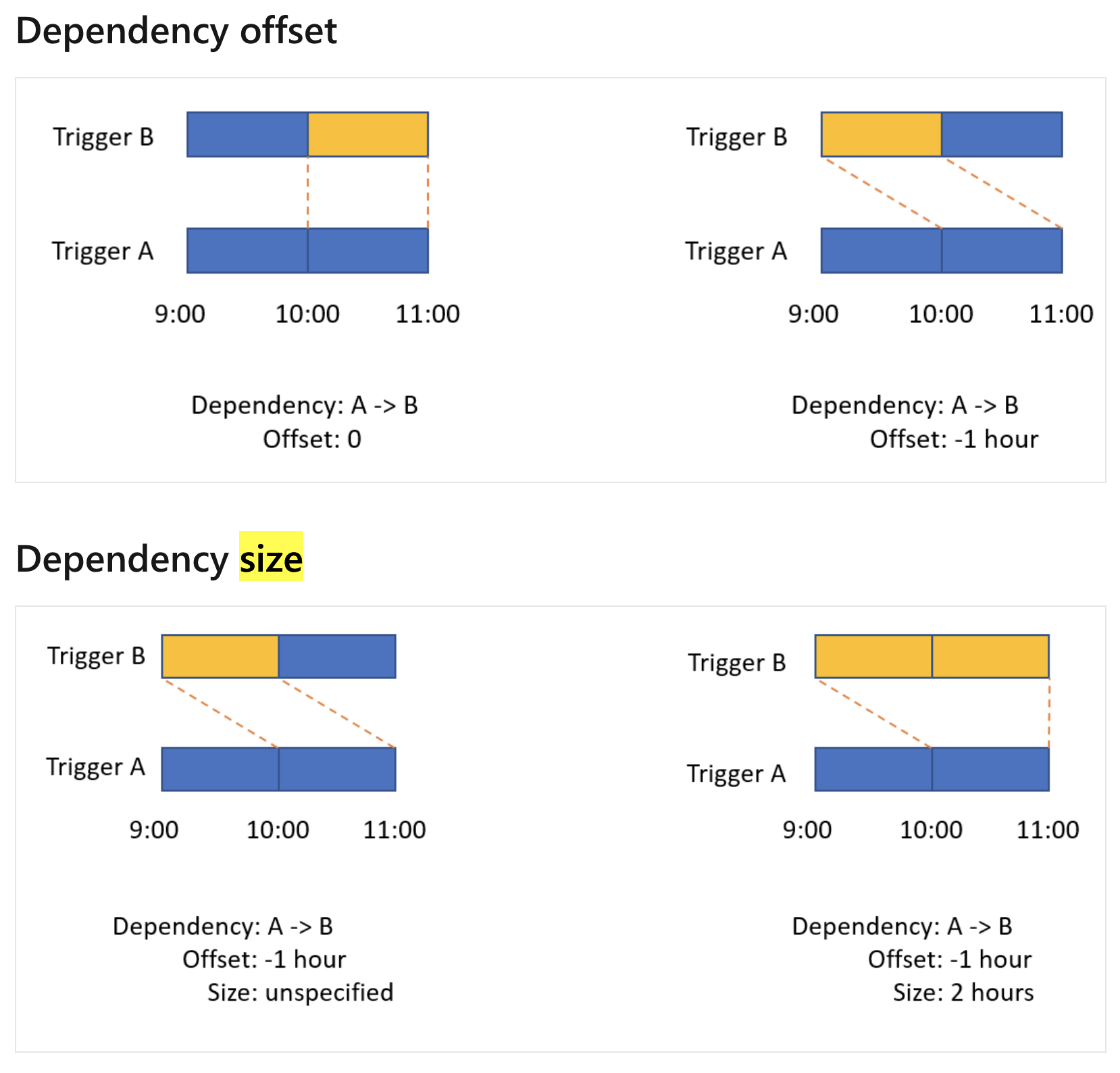
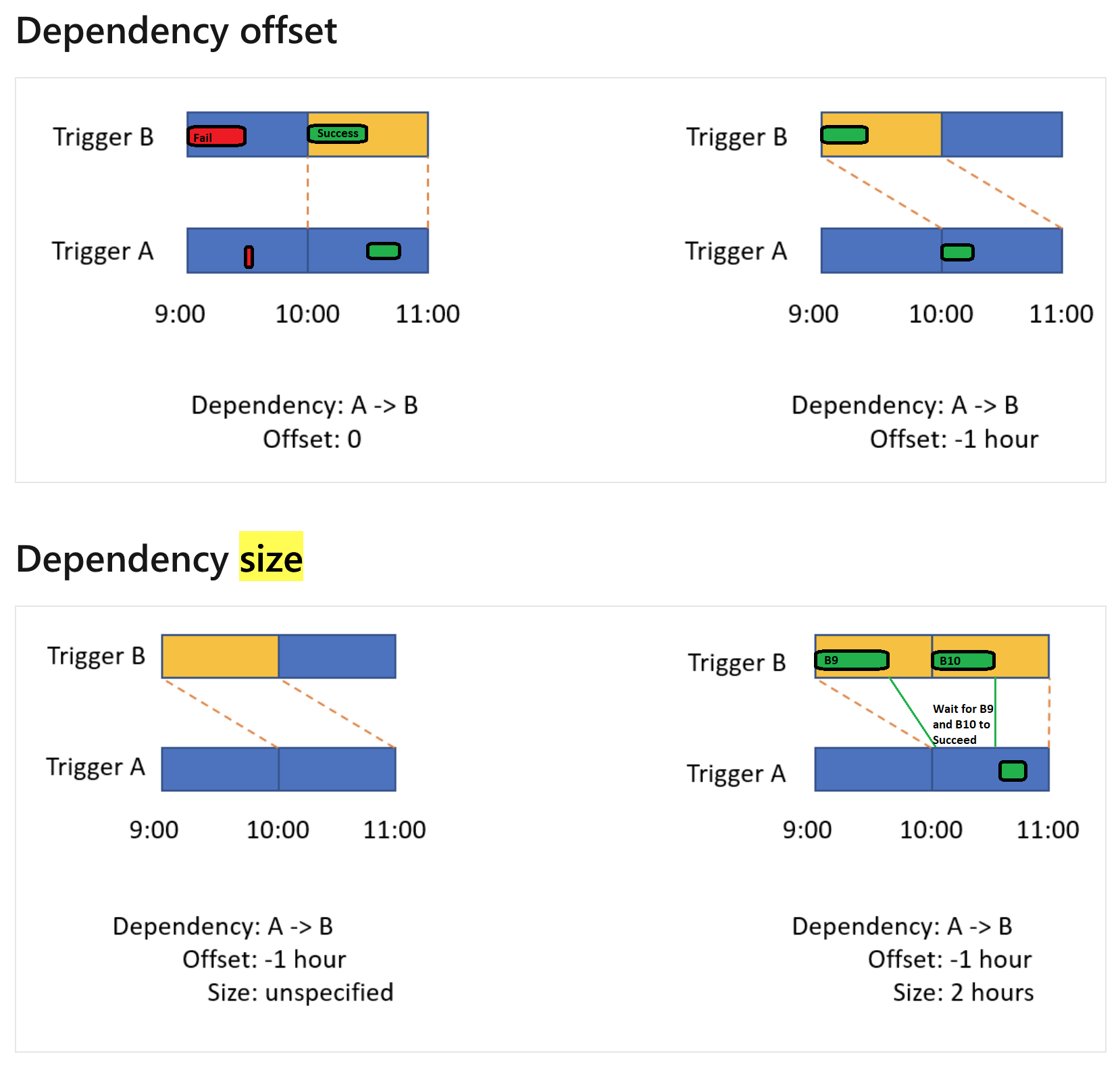
The Dependency Offset part seems clear. The second diagram in Dependency Offset tells me that Trigger A's 10 o clock run should depend on Trigger B's 9 o clock run.
The Dependency Size part does not quite make sense. How to make sense out of it/interpret it? e.g. the second example in the Dependency Size section where it says Offset is -1 hr and Size is 2 hrs. What is the size referring to here? The size 2hrs defined there is causing to have an overlap of 1 hr (i.e. between 10 and 11) with the complete window of Trigger A which effectively leaves Trigger A with no time to execute. I am sure I am interpreting it wrong. Could someone please help?
.
CodePudding user response:
Imagine you have a job that runs every hour to produce "usage metrics" for the past hour. Imagine "Trigger B" runs this job hourly.
Now you want a job (Trigger A) that creates a "rolling average" of usage metrics over the past two hours. To reduce computational requirements, you can produce this by taking the average of the usage metrics produced for the last two hours (calculations output by Trigger B).
You still run this "rolling average" ("Trigger A") job every hour, but it relies not only on the most recent "Trigger B" run that ran on this hour, but the previous one as well. The "Dependency Size" of 2 hours (with offset of -1 hour) means this trigger A will not run unless the 2 "Trigger B" jobs (from this hour and last hour) have both completed successfully.
Agreed that the diagram conveys the concept poorly for a number of reasons. For example in my opinion, Trigger B should be named A and vice-versa to make the dependency order more intuitively obvious.
Also, the individual/multiple pipeline runs should be visualized within the windows. Something like this might have been better: