With the python shift function, you are able to offset values by the number of rows. I'm looking to offset values by a specified time, which is 1 year in this case.
Here is my sample data frame. The value_py column is what I'm trying to return with a shift function. This is an over simplified example of my problem. How do I specify date as the offset parameter and not use rows?
import pandas as pd
import numpy as np
test_df = pd.DataFrame({'dt':['2020-01-01', '2020-08-01', '2021-01-01', '2022-01-01'],
'value':[10,13,15,14]})
test_df['dt'] = pd.to_datetime(test_df['dt'])
test_df['value_py'] = [np.nan, np.nan, 10, 15]
I have tried this but I'm seeing the index value get shifted by 1 year and not the value column
test_df.set_index('dt')['value'].shift(12, freq='MS')
Adding a follow-up question to this. How would I implement a groupby in the function provided by the accepted solution from @ali bakhtiari?
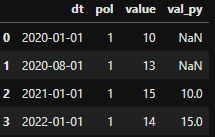
Sample DF
test_df = pd.DataFrame({'dt':['2020-01-01', '2020-08-01', '2021-01-01', '2022-01-01'],
'pol':[1,1,1,1],
'value':[10,13,15,14]})
test_df['dt'] = pd.to_datetime(test_df['dt'])
Attempted solution
test_df['val_py'] = test_df['dt'].map(test_df.set_index(['dt']).groupby('pol')['value'].shift(12, freq='MS'))
My attempted solution returns all NaN. Instead I'm looking to return the same output as provided by this
test_df['val_py'] = test_df['dt'].map(test_df.set_index('dt')['value'].shift(12, freq='MS'))
Expected output
CodePudding user response:
This should solve your problem:
test_df['new_val'] = test_df['dt'].map(test_df.set_index('dt')['value'].shift(12, freq='MS'))
test_df
dt value value_py new_val
0 2020-01-01 10 NaN NaN
1 2020-08-01 13 NaN NaN
2 2021-01-01 15 10.0 10.0
3 2022-01-01 14 15.0 15.0
Use .map() to map the values of the shifted dates to original dates.
Also you should use 12 as your shift parameter not -12.