I have a number of files like this:
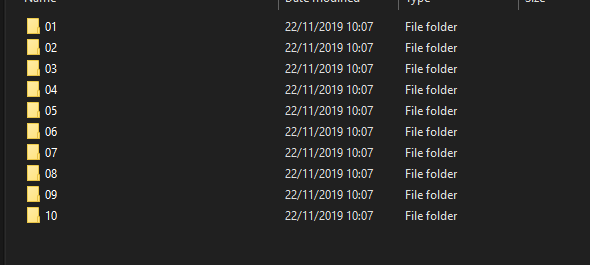
Inside each folder is 3 more like this:
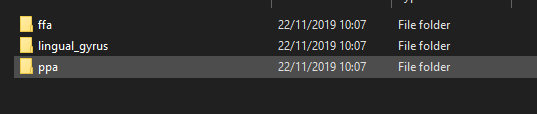
Now inside each of these folders is a .txt file that looks like this:

For each of the .txt files I need to get the value from the 6th column in the file which I have circled in red and I am only interested in the lines that contain cope1, cope2, cope3, cope4 and cope5 at the start (highlighted in blue). Everything else can be ignored.
I can't use PANDAS so I got this code using NUMPY but when I run it the output it only reads one file instead of 10.
this is the code I'm using:
import os
import numpy as np
li = []
# Traverses thru the root folder 'roi_data' tree and opens .txt files.
for root, dirs, files in os.walk('roi_data'):
for name in files:
# Opens .txt file as numpy array and uses the second and the sixth columns.
file_path = os.path.join(root, name)
arr = np.loadtxt(file_path, delimiter=' ', usecols=[1, 5], dtype=str)
# Filters out rows except those which contains 'cope'.
# Adds ROI columns based on the file dir.
arr = arr[np.char.startswith(arr[:, 0], 'stats/cope')]
roi = np.full(fill_value=root.split("/")[-1], shape=(5, 1))
arr = np.concatenate((roi, arr), axis=1)
# Adds files path to distinguish for which file the calculation is done.
# Appends the array to the list.
file_path = np.full(fill_value=file_path, shape=(5, 1))
arr = np.concatenate((arr, file_path), axis=1)
li.append(arr)
# Concatenates all extracted arrays.
# Calculates the requested metrics and builds the result_di
combined_arr = np.array(li).reshape((-1, 4))
groups = (np.char.array(combined_arr[:, 0])
'_' np.char.array(combined_arr[:, 1])).reshape((-1, 1))
combined_arr = np.concatenate((groups, combined_arr), axis=1)
result_di = dict()
for group in set(combined_arr[:, 0]):
group_slice = combined_arr[combined_arr[:, 0] == group]
values = (group_slice[:, 3].astype(float).mean(),
group_slice[:, 3].astype(np.float64).std(ddof=1),
group_slice[:, 3].astype(np.float64).shape[0])
result_di[group] = values
result_di = dict(sorted(result_di.items()))
print(result_di)
this is part of the output:
{'roi_data\\01\\ffa_stats/cope1': (0.2577, nan, 1), 'roi_data\\01\\ffa_stats/cope2': (0.2311, nan, 1), 'roi_data\\01\\ffa_stats/cope3': (0.6393, nan, 1),...
and this is how the output should be:
{'ffa_stats/cope1': (0.76427, 0.36723498396046694, 10),
'ffa_stats/cope2': (0.7036800000000001, 0.4011380360923157, 10),
'ffa_stats/cope3': (1.0842100000000001, 0.39293685511938314, 10),
'ffa_stats/cope4': (0.511365, 0.394306610851392, 10),
'ffa_stats/cope5': (0.92214, 0.4897486570794361, 10),
I would really appreciate some help understanding what is wrong with the code. In case it is necessary to test my code I share below a link to the files: https://wetransfer.com/downloads/9120b0776ba711364579fc3b4c1374c520230106104247/654a21
CodePudding user response:
In roi = np.full(fill_value=root.split("/")[-1], shape=(5, 1)) the split is done with "/" instead of "\", change it to roi = np.full(fill_value=root.split("\\")[-1], shape=(5, 1)) and it worked for me.