I am trying to scrape a table with data off a website with mouse-over color changing events and on each row only the first two columns have a class:
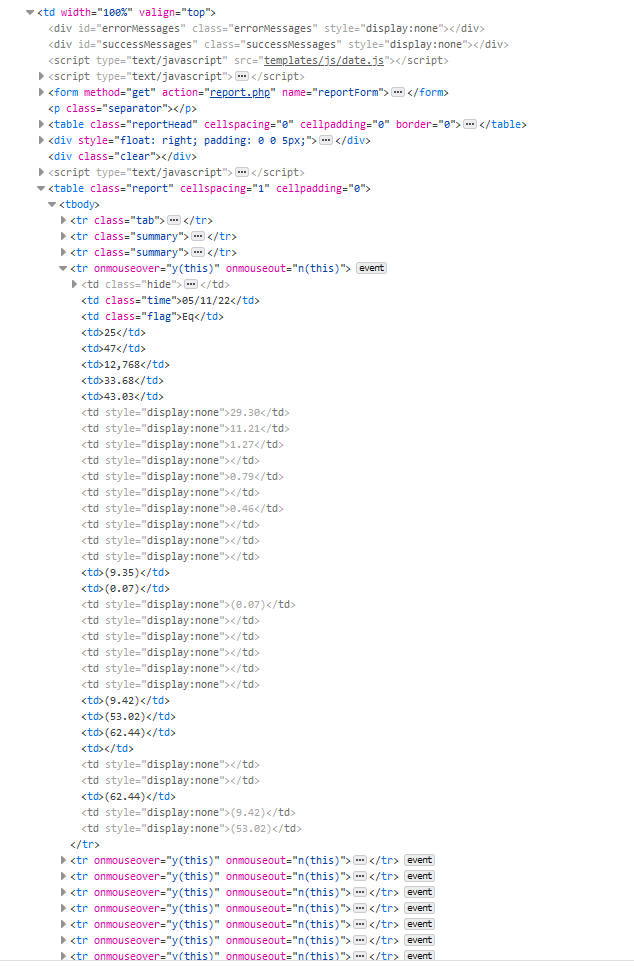
Additionally, when I do try to scrape those first two rows I get the output as such:
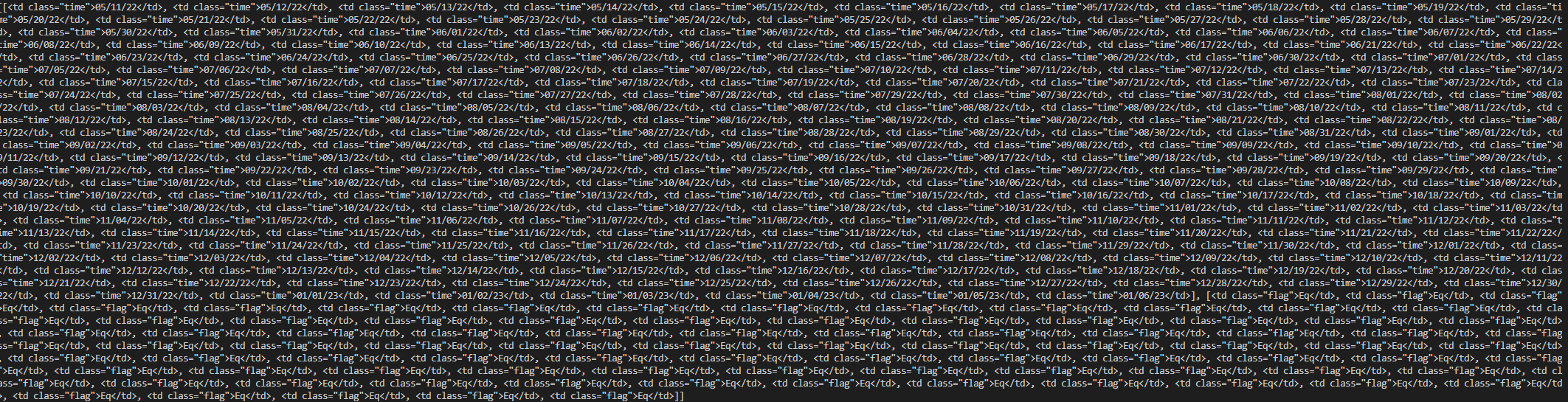
This is the code I am running.
lists = soup.find_all('table', class_= "report")
for list in lists:
date = list.find_all('td', class_= "time")
flag = list.find_all('td', class_= "flag")
info = [date, flag]
print(info)
I was expecting to receive only the numerical values so that I can export them and work with them.
I tried to use the .replace() function but it didn't remove anything.
I was unable to use .text even after converting date and flag to strings.
CodePudding user response:
Notes
It might be better to not use list as a variable name since it already means something in python....
Also, I can't test any of the suggestions below without having access to your HTML. It would be helpful if you include how you fetched the HTML to parse with BeautifulSoup. (Did you use some form of requests? Or something like selenium? Or do you just have the HTML file?) With requests or even selenium, sometimes the HTML fetched is not what you expected, so that's another issue...
The Reason behind the Issue
You can't apply .text/.get_text to the ResultSets (lists), which are what .find_all and .select return. You can apply .text/.get_text to Tags like the ones returned by .find or .select_one (but you should check first None was not returned - which happens when nothing is found).
So date[0].get_text() might have returned something, but since you probably want all the dates and flags, that's not the solution.
Solution Part 1 Option A: Getting the Rows with .find... chain
Instead of iterating through tables directly, you need to get the rows first (tr tags) before trying to get at the cells (td tags); if you have only one table with class= "report", you could just do something like:
rows = soup.find('table', class_= "report").find_all('tr', {'onmouseover': True})
But it's risky to chain multiple .find...s like that, because an error will be raised if any of them return None before reaching the last one.
Solution Part 1 Option B: Getting the Rows More Safely with .find...
It would be safer to do something like
table = soup.find('table', class_= "report")
rows = table.find_all('tr', {'onmouseover': True}) if table else []
or, if there might be more than one table with class= "report",
rows = []
for table in soup.find_all('table', class_= "report"):
rows = table.find_all('tr', {'onmouseover': True})
Solution Part 1 Option C: Getting the Rows with .select
However, I think the most convenient way is to use .select with CSS selectors
# if there might be other tables with report AND other classes that you don't want:
# rows = soup.select('table[] tr[onmouseover]')
rows = soup.select('table.report tr[onmouseover]')
this method is only unsuitable if there might be more than one table with class= "report", but you only want rows from the first one; in that case, you might prefer the table.find_....if table else [] approach.
Solution Part 2 Option A: Iterating Over rows to Print Cell Contents
Once you have rows, you can iterate over them to print the date and flag cell contents:
for r in rows:
date, flag = r.find('td', class_= "time"), r.find('td', class_= "flag")
info = [i.get_text() if i else i for i in [date, flag]]
if any([i is not None for i in info]): print(info)
# [ only prints if there are any non-null values ]
Solution Part 2 Option B: Iterating Over rows with a Fucntion
Btw, if you're going to be extracting multiple tag attributes/texts repeatedly, you might find my selectForList function useful - it could have been used like
for r in rows:
info = selectForList(r, ['td.time', 'td.flag'], printList=True)
if any([i is not None for i in info]): print(info)
or, to get a list of dictionaries like [{'time': time_1, 'flag': flag_1}, {'time': time_2, 'flag': flag_2}, ...],
infList = [selectForList(r, {
'time': 'td.time', 'flag': 'td.flag', ## add selectors for any info you want
}) for r in soup.select('table.report tr[onmouseover]')]
infList = [d for d in infoList if [v for v in d.values() if v is not None]]
Added EDIT:
To get all displayed cell contents:
for r in rows:
info = [(td.get_text(),''.join(td.get('style','').split())) for td in r.select('td')]
info = [txt.strip() for txt, styl in r.select('td') if 'display:none' not in styl]
# info = [i if i else 0 for i in info] # fill blanks with zeroes intead of ''
if any(info): print(info) ## or write to CSV