I have a data frame as shown below. I want to compute the trends of all numeric columns and if they are significant or not per name.
library(EnvStats)
dat=structure(list(date = c("1983-12-01", "1984-01-01",
"1984-02-01",
"1984-03-01", "1984-04-01", "1984-05-01"),
rig = c(68.1, 62.4,
67.5, 78.9, 81.7, 72.2), pass = c(9.57, 10.49, 11.97,
11.43, 9.54,
8.98), name = structure(c(1L, 2L, 3L, 4L, 5L, 6L), levels =
c("az", "az", "nc", "nc", "et", "et"), class = "factor")),
row.names = c(NA, 6L), class = "data.frame")
Is there a function in R to do this? We can use:
kendallTrendTest(rig ~ date)
but how should I do this to have the output like this for all colums?:
name rig_trend_slope rig_trend_pvalue pass_trend_slope pass_trend_pvalue
az
nc
et
CodePudding user response:
As @Quiten mentioned the number of observations in the data are limited, so a group by approach would return error. If we want to do this on multiple columns, loop across the columns in summarise, extract the needed components from the list output as a tibble and then use unnest_wider to create wide dataset
library(dplyr)
library(tidyr)
library(EnvStats)
library(tibble)
library(flextable)
library(officer)
dat1 <- dat %>%
mutate(date2 = as.numeric(as.Date(date))) %>%
# group_by(name) %>%
# or use reframe in the devel version
summarise(across(rig:pass, ~
{tmp <- kendallTrendTest(reformulate('date2',
response = cur_column()))
tibble(trend_slope = tmp$estimate['slope'],
trend_pvalue = tmp$p.value)})) %>%
unnest_wider(where(is_tibble), names_sep = "_") %>%
flextable %>%
colformat_double(i=1,digit=2 )
for(nm in dat1$col_keys)
{dat1 <- dat1 %>%
color(i= as.formula(sprintf("~%s<0", nm)), j=nm, color="red")
}
-output

To save as word format, we may use save_as_docx from officer package
tf <- tempfile(fileext = ".docx")
save_as_docx(
dat1, path = tf
)
-output
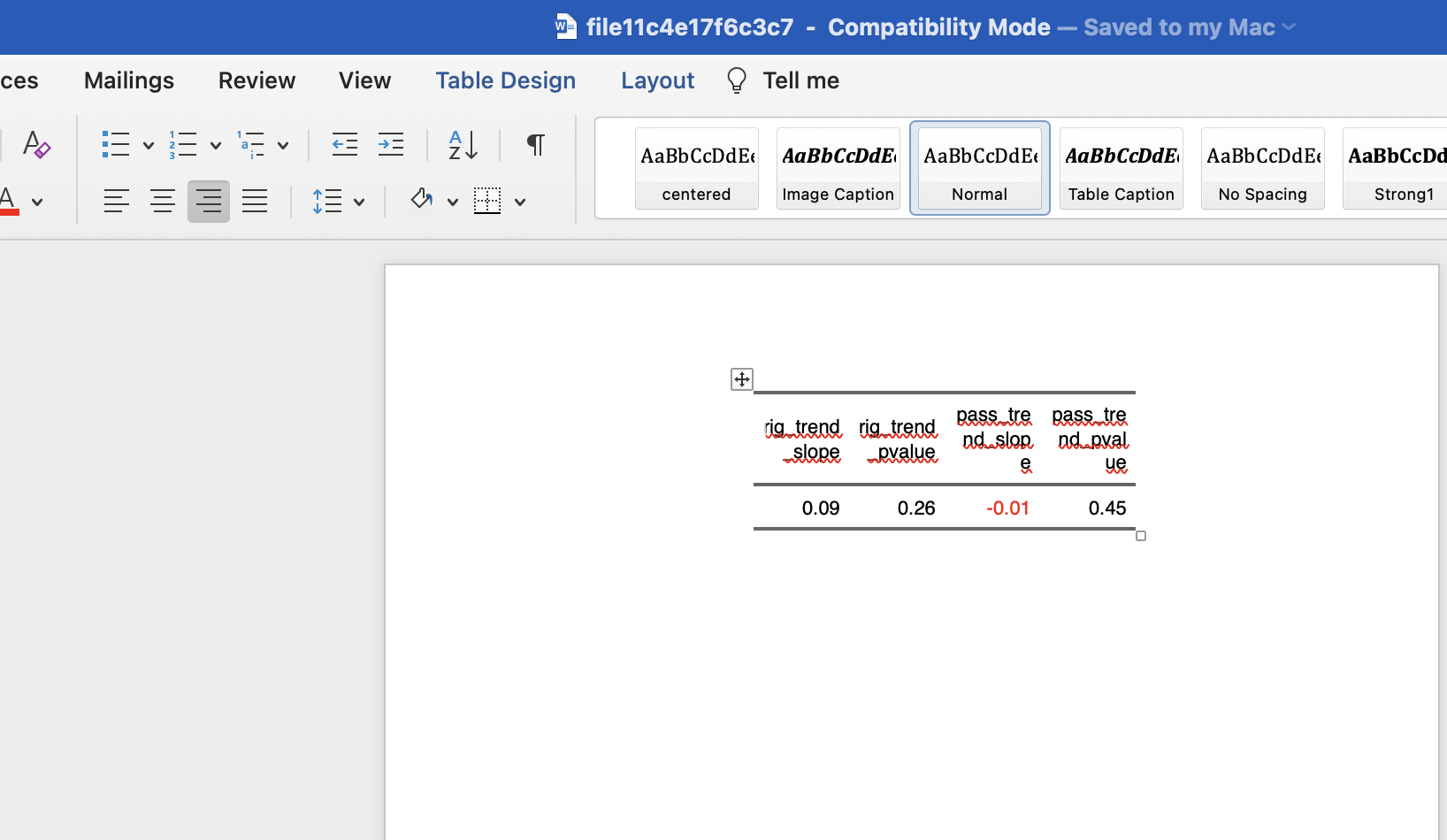
NOTE: Here the group_by(name) is commented as there are only 2 observations and it returns in error for all the cases. With the full dataset, uncomment the group_by(name)
The broom::tidy seems to have an issue with the class from kendallTrendTest
CodePudding user response:
First, you only have two values per group which is not ideal. To calculate the trend per group you could use dplyr with group_by and do to perform the test. Also make sure your x variable in your kendallTrendTest is numeric. You could use tidy to get some coefficients. Here is a reproducible example:
library(dplyr)
library(EnvStats)
library(broom)
models <- dat %>%
mutate(date2 = as.numeric(as.Date(date))) %>%
group_by(name) %>%
do(model = kendallTrendTest(rig ~ date2, data = .))
models %>%
broom::tidy(model)