Don't know if this is the best way to describe this but I have two columns A and B and I need to combine the counts of A and B as the same as B and A (Specifically airports if anyone is interested, however for this business application NYC => LA is the same as LA => NYC so I'm trying to combine areas where NYC => LA and LA => NYC as the same.)
I've tried a few things in Python to get this done. I did something at a previous job a few years ago so I know it's not hard just Tuesday brain. Goal would be a simple code snippet that allows me to combine the counts of A=>B and B=>A as one.
CodePudding user response:
Assuming your file looks like that:
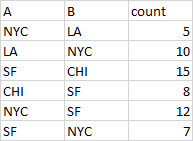
import pandas as pd
df = pd.read_csv('file.csv')
pairs = set(tuple(sorted(x)) for x in df[['A','B']].to_numpy()) # create a set of tuples containing unique pairs of airports
combined_counts = {} # create a new dictionary to store the combined counts
# iterate over the pairs of airports
for pair in pairs:
airport1, airport2 = pair
# add the counts of A=>B and B=>A together
count = df[(df['A'] == airport1) & (df['B'] == airport2)]['count'].sum() df[(df['A'] == airport2) & (df['B'] == airport1)]['count'].sum()
# store the result in the new dictionary
combined_counts[pair] = count
df_result = pd.DataFrame(list(combined_counts.items()), columns = ['Airport Pair', 'Count'])
print(df_result)
Output will be:
Airport Pair Count
0 (LA, NYC) 15
1 (CHI, SF) 23
2 (NYC, SF) 19