mydata<-structure(list(Weight = c(66.2, 65.2, 69.8, 63.4, 67.4, 66.3,
63.8, 67.8, 66.7, 66.2, 61.9, 66.9, 69.4, 60.8, 64.1, 62.8, 62.5,
60.9, 61.3, 67.8), Age = c(68, 67, 65, 65, 63, 64, 68, 65, 65,
71, 64, 65, 68, 61, 65, 62, 60, 66, 62, 58),
Sex = c("H", "H",
"H", "H", "H", "H", "F", "F", "F", "F", "H", "H", "H", "F", "F",
"F", "F", "F", "F", "F"),
Group = c("G1", "G1", "G1", "G1",
"G1", "G1", "G1", "G1", "G1", "G1", "G2", "G2", "G2", "G2", "G2",
"G2", "G2", "G2", "G2", "G2")), row.names = c(NA, -20L),
class = "data.frame")
I want to summarize my data by creating my table manually. My goal is to compare variables between two groups. I don't know of any software that allows me to have a confidence interval of the difference of the mean and the p-value, in a table format. I have to export my data with Rmarkdown in word format, so I should have it in table format.
I created all the parameters like this:
confInt<-paste(round(t.test(mydata$Weight~mydata$Group)$conf.int[1],2),
round(t.test(mydata$Weight~mydata$Group)$conf.int[2],2),sep = ";")
p.value<-round(t.test(mydata$Weight~mydata$Group)$p.value,3)
mean1<-mean(mydata$Weight[mydata$Group=="G1"])
mean2<-mean(mydata$Weight[mydata$Group=="G2"])
mean_diff<-(mean(mydata$Weight[mydata$Group=="G1"])-
mean(mydata$Weight[mydata$Group=="G2"]))
The goal is to create these parameters for each of my numeric variables, via a loop or a function. First for the variable Weight:
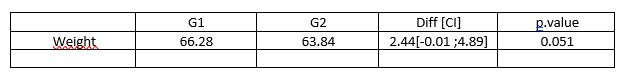
Then via a rowbind , bind the statistics of each variable

CodePudding user response:
We can create a function that takes in data mydata, numeric column col and grouping column group:
summary_val <- function(mydata,col,group){
x <- mydata[[col]]
group_data <- mydata[[group]]
confInt<-paste(round(t.test(x~group_data)$conf.int[1],2),
round(t.test(x~group_data)$conf.int[2],2),sep = ";")
p.value<-round(t.test(x~group_data)$p.value,3)
mean1<-mean(x[group_data=="G1"])
mean2<-mean(x[group_data=="G2"])
mean_diff<-(mean(x[group_data=="G1"])-
mean(x[group_data=="G2"]))
diff <- paste0(mean_diff,"[",confInt,"]")
return(data.frame(var=col,G1=mean1,G2=mean2,`Diff.CI.`=diff,`p.value`=p.value))
}
summary_val(mydata,"Weight","Group")
var G1 G2 Diff.CI. p.value
1 Weight 66.28 63.84 2.44[-0.01;4.89] 0.051
Then we can use the following to extract the names of numeric columns:
num_var <- names(mydata)[unlist(lapply(mydata, is.numeric))]
num_var
[1] "Weight" "Age"
And get the summary output via for loop:
mysummary <- data.frame()
for(var in num_var){
mysummary <- rbind(mysummary,summary_val(mydata,var,"Group"))
}
mysummary
var G1 G2 Diff.CI. p.value
1 Weight 66.28 63.84 2.44[-0.01;4.89] 0.051
2 Age 66.10 63.10 2.99999999999999[0.43;5.57] 0.025
or using do.call lapply
summary_val2 <- function(col,mydata,group){
summary_val(mydata,col,group)
}
do.call(rbind,lapply(num_var,summary_val2,mydata,"Group"))
var G1 G2 Diff.CI. p.value
1 Weight 66.28 63.84 2.44[-0.01;4.89] 0.051
2 Age 66.10 63.10 2.99999999999999[0.43;5.57] 0.025