Imagine a dataframe:
df1 <- tibble::tribble( ~City, ~Year, ~Burger_cost, ~Cola_cost, ~Resident_AVGGrowth_cm,
"Abu Dhabi", 2020, 2, 3, 175,
"Abu Dhabi", 2019, 1, 3, 174,
"Abu Dhabi", 2018, 1, 2, 173,
"New York", 2020, 4, 5, 500,
"New York", 2019, 3, 5, 184,
"New York", 2018, 2, 3, 183,
"Abu Dhabi", 2020, 2, 3, 175,
"Abu Dhabi", 2019, 1, 3, 174,
"Abu Dhabi", 2018, 1, 2, 173,
"Abu Dhabi", 2017, 1, NA, 100,
"London", 2020, 5, 6, 186,
"London", 2019, 4, 6, 188,
"London", 2018, 3, 5, 185,
"New York", 2020, 4, 5, 185,
"New York", 2019, 3, 5, 184,
"New York", 2018, 3, 3, 183,
"London", 2020, 5, 6, 186,
"London", 2019, 4, 6, 188,
"London", 2018, 3, 5, 185)
The same dataset for visual representation:
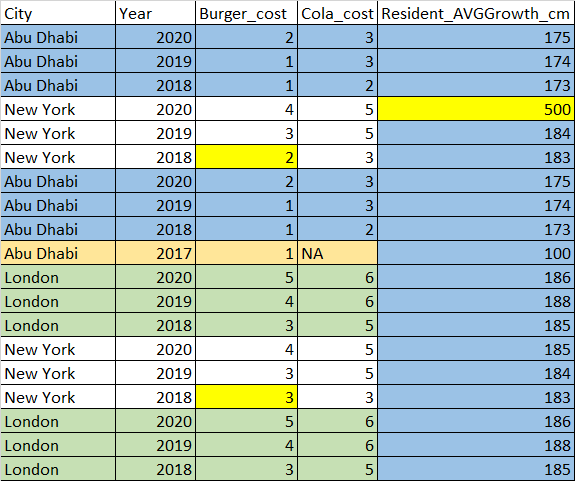
There can be many inputs. For example, data for London is totally similar for all years, so we can delete it. The data for Abu Dhabi is similar for years 2018-2020 and has difference for 2017. The data for New York contains discrepancy in year 2018 for the Burger cost (and growth of a city resident). The data for the growth of a city resident is surely erroneus in row 4 for NY (too huge descrepancy), but it has a duplicate value in the row 16 (in this case we would prefer delete row 4 and keep row 16 based on criteria that no person can be shorter than 50 cm and longer than 4 meters [400 cm] [especially in the mean values :)]). Rows 6 and 16 (for NY, 2018) contain different data for the burger cost which can only be resolved by human (say, variant with 3 USD is correct but R needs to show the fact of discrepancy for the end user).
The question: can you suppose nice and neat methods for performing these operations? What do you usually use to solve such issues.
I just started to think on this issue. It is an easy task in C#. I am keeping in mind several strategies, but I would be extremely interested to know what ways do you use for solving such issues :) Any ideas are much appreciated :)
CodePudding user response:
Perhaps this helps - Grouped by 'City', create a flag for the outliers with boxplot on the 'Resident_AVGGrowth_cm', then add 'Year' into the grouping, create another flag for unique values based on the columns Burger_cost to Resident_AVGGrowth_cm using n_distinct and looping over if_all (returns TRUE only if all the columns looped for the row are returning TRUE), then grouped by City, filter out those City having all duplicates e.g. London, as well as remove the rows with outlier_flag
library(dplyr)
df1 %>%
group_by(City) %>%
mutate(outlier_flag = Resident_AVGGrowth_cm %in%
boxplot(Resident_AVGGrowth_cm, plot = FALSE)$out) %>%
group_by(Year, .add = TRUE) %>%
mutate(flag_all_unq = if_all(Burger_cost:Resident_AVGGrowth_cm,
~ n_distinct(.x, na.rm = TRUE) == 1)) %>%
group_by(City) %>%
filter(!all(flag_all_unq)) %>%
ungroup %>%
filter((!outlier_flag)|flag_all_unq)