I have the following data structure in JSON file and would like to flatten the data.
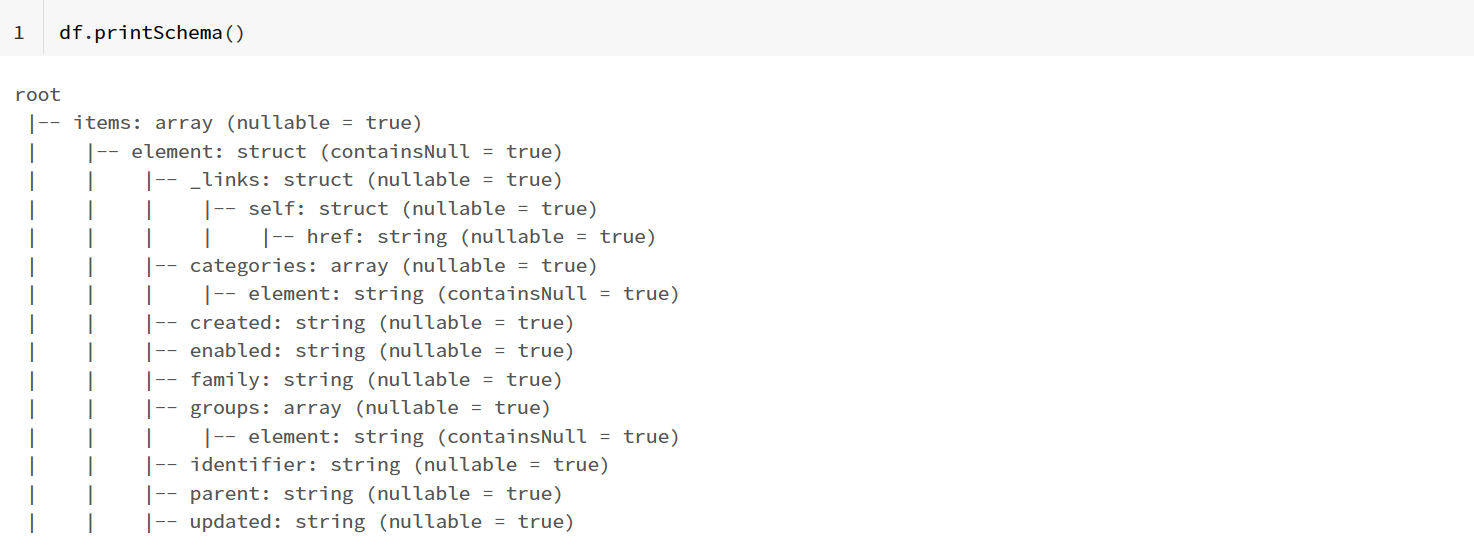
root
|-- _embedded: struct (nullable = true)
| |-- items: array (nullable = true)
| | |-- element: struct (containsNull = true)
| | | |-- _links: struct (nullable = true)
| | | | |-- self: struct (nullable = true)
| | | | | |-- href: string (nullable = true)
| | | |-- associations: struct (nullable = true)
| | | | |-- ERP_PIM: struct (nullable = true)
| | | | | |-- groups: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- product_models: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- products: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | |-- PACK: struct (nullable = true)
| | | | | |-- groups: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- product_models: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- products: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | |-- SUBSTITUTION: struct (nullable = true)
| | | | | |-- groups: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- product_models: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- products: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | |-- UPSELL: struct (nullable = true)
| | | | | |-- groups: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- product_models: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- products: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | |-- X_SELL: struct (nullable = true)
| | | | | |-- groups: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- product_models: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | | | |-- products: array (nullable = true)
| | | | | | |-- element: string (containsNull = true)
| | | |-- categories: array (nullable = true)
| | | | |-- element: string (containsNull = true)
| | | |-- created: string (nullable = true)
| | | |-- enabled: boolean (nullable = true)
| | | |-- family: string (nullable = true)
| | | |-- groups: array (nullable = true)
| | | | |-- element: string (containsNull = true)
| | | |-- identifier: string (nullable = true)
| | | |-- metadata: struct (nullable = true)
| | | | |-- workflow_status: string (nullable = true)
| | | |-- parent: string (nullable = true)
| | | |-- updated: string (nullable = true)
| | | |-- values: struct (nullable = true)
| | | | |-- Contrex_table: array (nullable = true)
| | | | | |-- element: struct (containsNull = true)
| | | | | | |-- data: string (nullable = true)
| | | | | | |-- locale: string (nullable = true)
| | | | | | |-- scope: string (nullable = true)
| | | | |-- UFI_Table: array (nullable = true)
| | | | | |-- element: struct (containsNull = true)
| | | | | | |-- data: array (nullable = true)
| | | | | | | |-- element: struct (containsNull = true)
| | | | | | | | |-- UFI: string (nullable = true)
| | | | | | | | |-- company: string (nullable = true)
| | | | | | |-- locale: string (nullable = true)
| | | | | | |-- scope: string (nullable = true)
| | | | |-- add_reg_info: array (nullable = true)
| | | | | |-- element: struct (containsNull = true)
| | | | | | |-- data: string (nullable = true)
| | | | | | |-- locale: string (nullable = true)
| | | | | | |-- scope: string (nullable = true)
| | | | |-- adr_transport_class: array (nullable = true)
| | | | | |-- element: struct (containsNull = true)
| | | | | | |-- data: string (nullable = true)
| | | | | | |-- locale: string (nullable = true)
| | | | | | |-- scope: string (nullable = true)
| | | | |-- adr_transport_label: array (nullable = true)
| | | | | |-- element: struct (containsNull = true)
| | | | | | |-- data: array (nullable = true)
| | | | | | | |-- element: string (containsNull = true)
| | | | | | |-- locale: string (nullable = true)
| | | | | | |-- scope: string (nullable = true)
| | | | |-- adr_tunnel_restriction_code: array (nullable = true)
| | | | | |-- element: struct (containsNull = true)
| | | | | | |-- data: string (nullable = true)
| | | | | | |-- locale: string (nullable = true)
| | | | | | |-- scope: string (nullable = true)
| | | | |-- allergen: array (nullable = true)
| | | | | |-- element: struct (containsNull = true)
| | | | | | |-- data: array (nullable = true)
| | | | | | | |-- element: string (containsNull = true)
| | | | | | |-- locale: string (nullable = true)
| | | | | | |-- scope: string (nullable = true)
| | | | |-- api: array (nullable = true)
| | | | | |-- element: struct (containsNull = true)
| | | | | | |-- data: string (nullable = true)
| | | | | | |-- locale: string (nullable = true)
| | | | | | |-- scope: string (nullable = true)
|-- _links: struct (nullable = true)
| |-- first: struct (nullable = true)
| | |-- href: string (nullable = true)
| |-- next: struct (nullable = true)
| | |-- href: string (nullable = true)
| |-- self: struct (nullable = true)
| | |-- href: string (nullable = true)
short version of data.
{"items": [
{
"_links": {
"self": {
"href": "products\/PCR-0006894-SAMKG0-PC"
}
},
"identifier": "pcr-1",
"enabled": true,
"family": "products",
"categories": [
"239",
"CL1_MEA",
"D00",
"D001",
"EMEA",
"MAR",
"MARKET_SEGMENT_VIEW",
"PC",
"Validated_SHEQ"
],
"groups": [],
"parent": "PCR-0006894-SAMKG0"
}]}
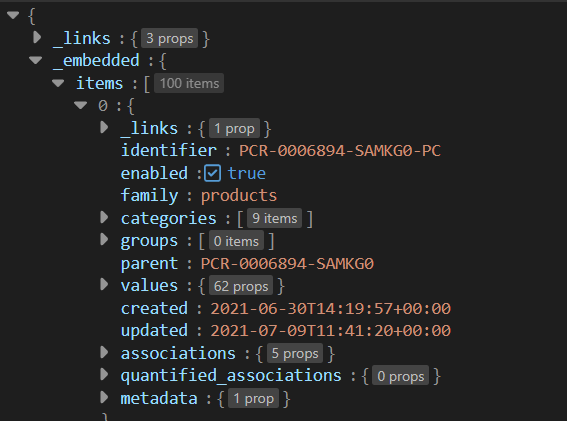
Goal is to not mentione keys manually but explode only the one which values are str type.
I have this code where I im trying to flatten the entire json file:
def flatten_df(nested_df):
flat_cols = [c[0] for c in nested_df.dtypes if c[1][:6] != 'struct']
nested_cols = [c[0] for c in nested_df.dtypes if c[1][:6] == 'struct']
flat_df = nested_df.select(flat_cols
[F.col(nc '.' c).alias(nc '_' c)
for nc in nested_cols
for c in nested_df.select(nc '.*').columns])
return flat_df
Desired output:

CodePudding user response:
I have taken the sample data that you have given (added another element to items array). Then, I have created a dataframe from this data.
data = '''{
"items":[
{
"_links":{
"self":{
"href":"products\/PCR-0006894-SAMKG0-PC"
}
},
"identifier":"pcr-1",
"enabled":"true",
"family":"products",
"categories":[
"239",
"CL1_MEA",
"D00",
"D001",
"EMEA",
"MAR",
"MARKET_SEGMENT_VIEW",
"PC",
"Validated_SHEQ"
],
"groups":[
],
"parent":"PCR-0006894-SAMKG0",
"created":"2021-01-01T12:00:00 00:00",
"updated":"2021-01-01T12:00:00 00:00"
},
{
"_links":{
"self":{
"href":"products\/PCR-0006894-SAMKG0-PC"
}
},
"identifier":"pcr-2",
"enabled":"true",
"family":"products",
"categories":[
"239",
"CL1_MEA",
"D00",
"D001",
"EMEA",
"MAR",
"MARKET_SEGMENT_VIEW",
"PC",
"Validated_SHEQ"
],
"groups":[
],
"parent":"PCR-0006783-SAMKG0",
"created":"2022-04-01T12:00:00 00:00",
"updated":"2022-04-01T12:00:00 00:00"
}
]
}'''
x = []
x.append(data)
df = spark.read.json(sc.parallelize(x))
#df.printSchema()
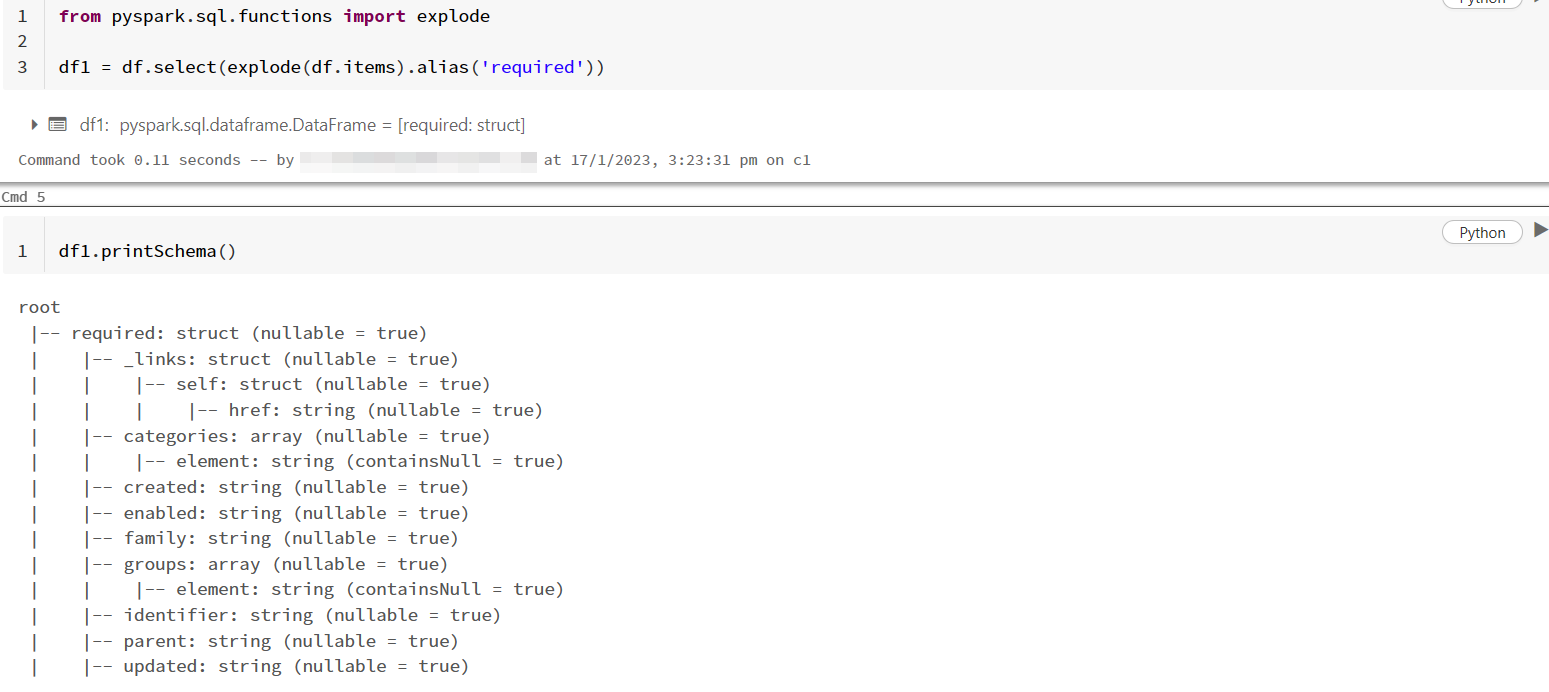
- Now, I have used
explodefunction on theitemscolumn to create a new dataframe.
from pyspark.sql.functions import explode
df1 = df.select(explode(df.items).alias('required'))
df1.printSchema()
- Now, I have created another dataframe selecting all the columns from
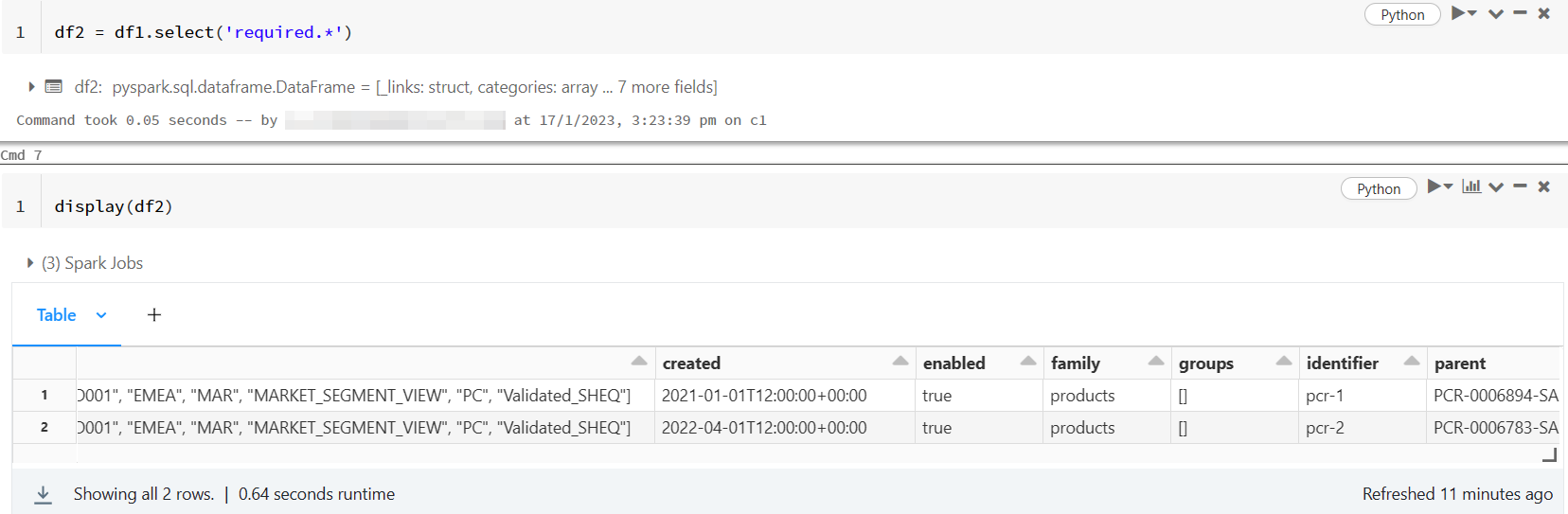
requiredstruct column using the following code:
df2 = df1.select('required.*')
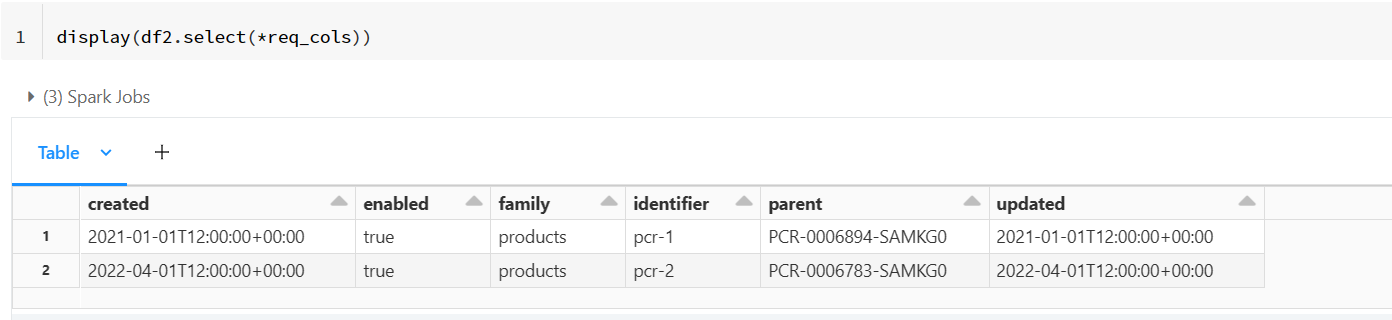
display(df2)
- Now, using the following code, I have created an array containing column names whose type is
string.
req_cols = []
for col_name,col_type in df2.dtypes:
#print(col_name,col_type)
if(col_type == 'string'):
req_cols.append(col_name)
print(req_cols)

- Now you can use the above array to select the required columns from the
df2dataframe.
display(df2.select(*req_cols))