How can I R to identify in columns other than an ID column, the year specified at the end of each column (which follows a variety of characters), then place corresponding rows in a new data frame with that year expressed as a new column, and finally have a new column that simply removes the year from the original column names and eliminates any underscore that now appears at the end of the column name?
For example, I want to convert a data frame of 2 records with 5 columns named col1, col2_1980, col2_1981, col3_1980, and col3_1981 in which col1 is a character value (either "a", or "b") into a data frame with 4 records that has col1 = "a" for 2 records, and col1 = "b" for 2 records, and then col2 = "1980" for 1 record per col1 value and col2 = "1981" for 1 record per col1 value.
Uses of 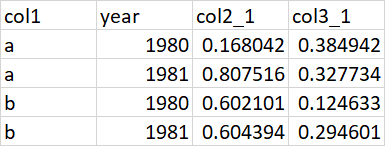
CodePudding user response:
pivot_longer() can handle patterns / separators in names.
With updated dataset:
library(dplyr)
library(tidyr)
set.seed(3)
df1 <-
rbind(
data.frame(
col1 = "a",
col2_1_1980 = runif(1),
col2_1_1981 = runif(1),
col3_1_1980 = runif(1),
col3_1_1981 = runif(1)),
data.frame(
col1 = "b",
col2_1_1980 = runif(1),
col2_1_1981 = runif(1),
col3_1_1980 = runif(1),
col3_1_1981 = runif(1)))
df1 %>% pivot_longer(
cols = contains("_"),
names_pattern = "(.*)_(\\d )$",
names_to = c(".value", "year"))
#> # A tibble: 4 × 4
#> col1 year col2_1 col3_1
#> <chr> <chr> <dbl> <dbl>
#> 1 a 1980 0.168 0.385
#> 2 a 1981 0.808 0.328
#> 3 b 1980 0.602 0.125
#> 4 b 1981 0.604 0.295
Original sample data in question included column names like col2_1980 & col2_1981 , for those names_sep param serves well:
df1 %>% pivot_longer(
cols = contains("_"),
names_sep = "_",
names_to = c(".value", "year"))
#> # A tibble: 4 × 4
#> col1 year col2 col3
#> <chr> <chr> <dbl> <dbl>
#> 1 a 1980 0.168 0.385
#> 2 a 1981 0.808 0.328
#> 3 b 1980 0.602 0.125
#> 4 b 1981 0.604 0.295
Created on 2023-01-18 with reprex v2.0.2
CodePudding user response:
Please try the below code , accomplished the expected result using pivot_longer, pivot_wider
code
library(dplyr)
df2 <- df1 %>% pivot_longer(c(contains('_'))) %>%
mutate(year=str_extract(name,'(?<=\\_)\\d.*'), name=str_extract(name,'^.*(?=\\_)')) %>%
pivot_wider(c(col1,year), names_from = 'name', values_from = 'value')