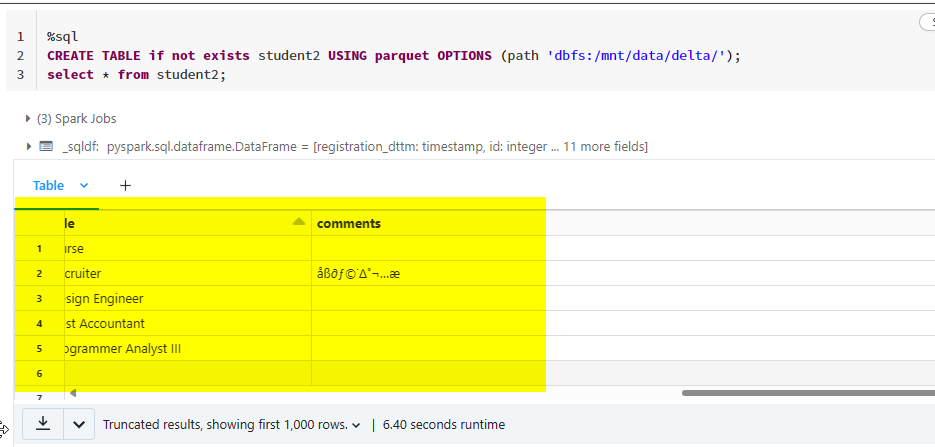
I'm creating a external table in azure databricks on top of the ADLS parquet files using the syntax below.
create table if not exists <table_name> using parquet location 'abfss://@'
This syntax will automatically infer the schema of the parquet file and create external table, now my question is when there is multiple files available(specially when files are different in structure) in the specified location, which file databricks will refer?
Most recent one or oldest one or random?
CodePudding user response:
I have reproduced the above and got below results.
These are my two parquet files with different schema as one will have less column than another.
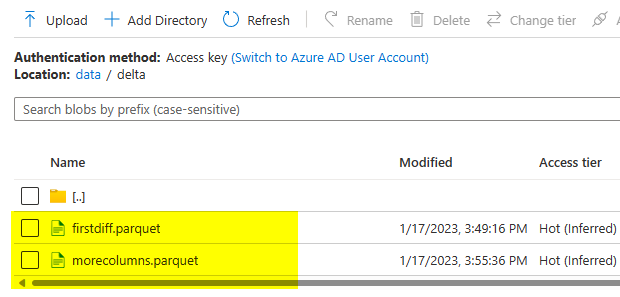
when I created the table from the folder it took the only first file which means as in alphabetical order.
%sql
CREATE TABLE if not exists student1 USING parquet OPTIONS (path 'dbfs:/mnt/data/delta/');
select * from student1;
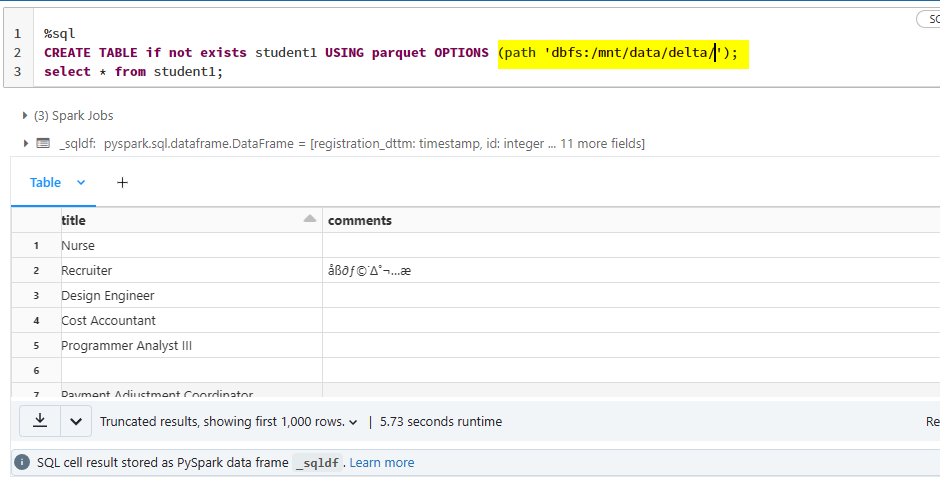
And its the same with pyspark dataframe also.