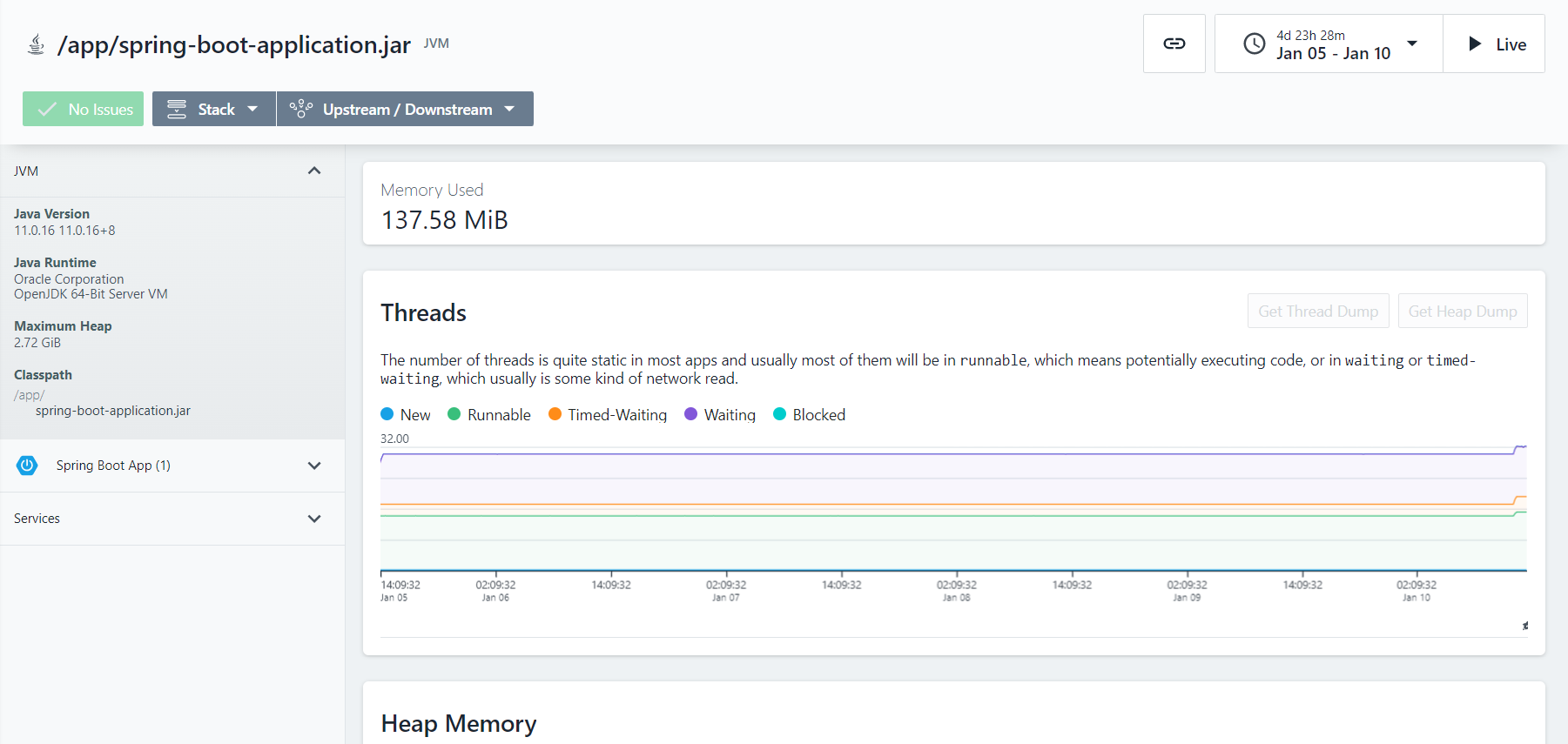
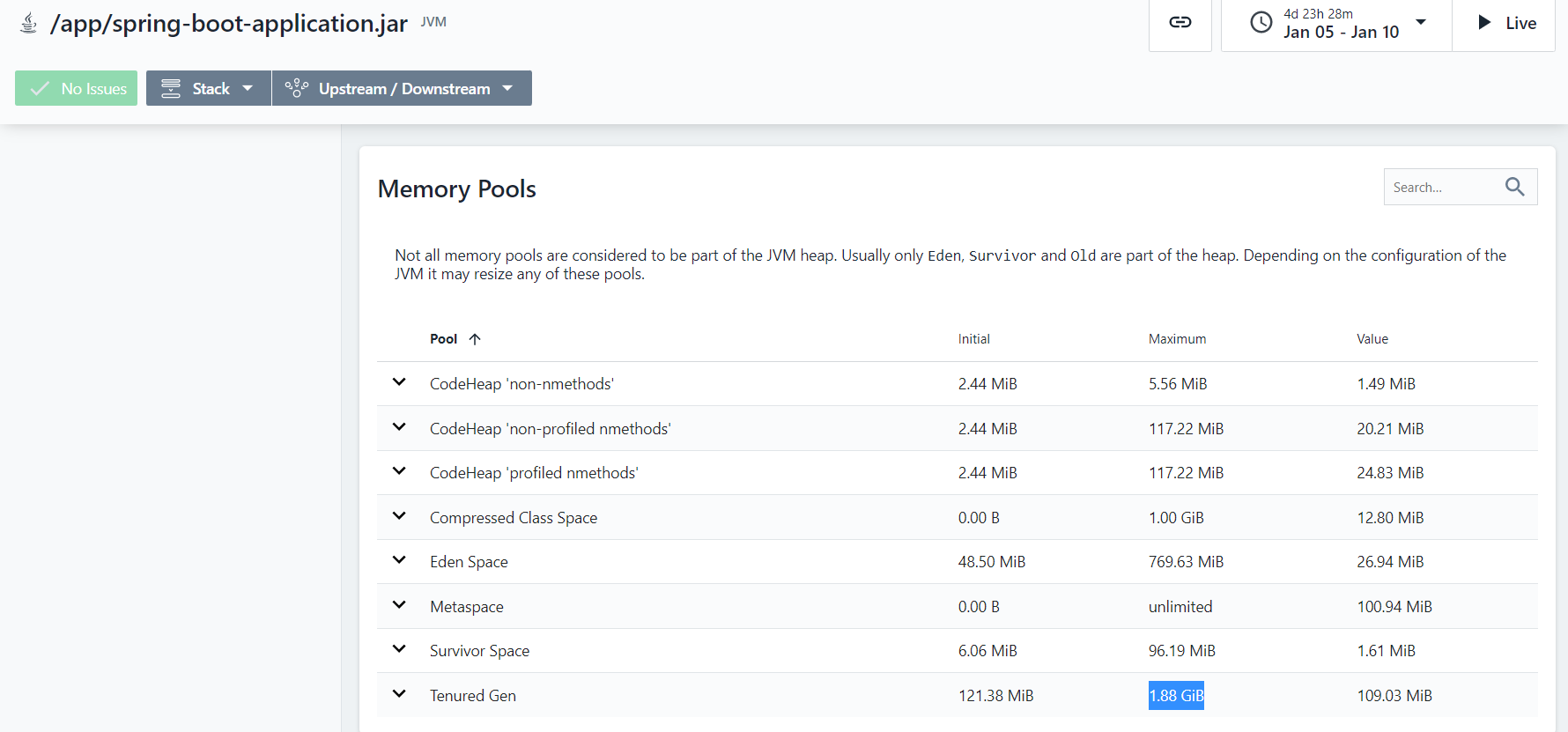
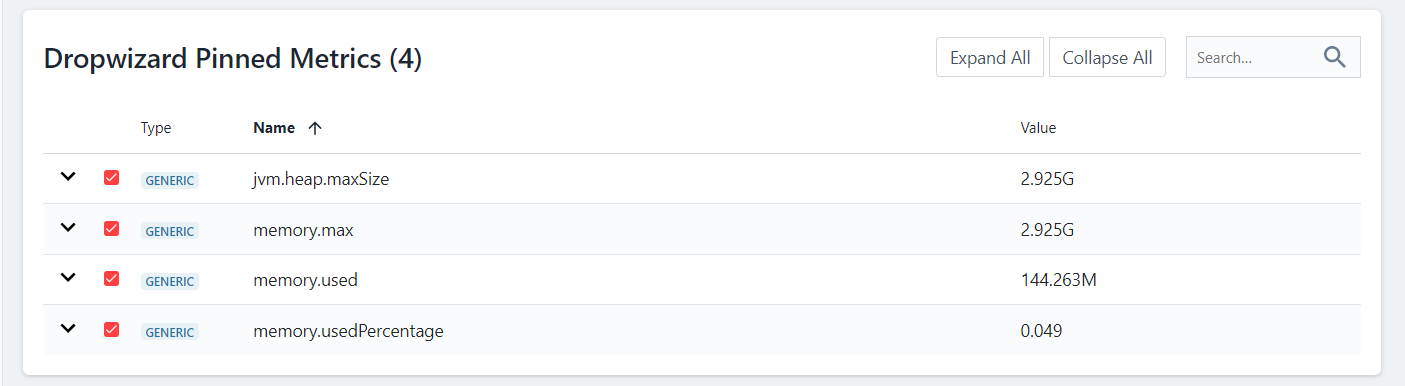
I have an issue that some of our microservices have a memory allocation spike that triggers an OOMKiller Kubernetes event.
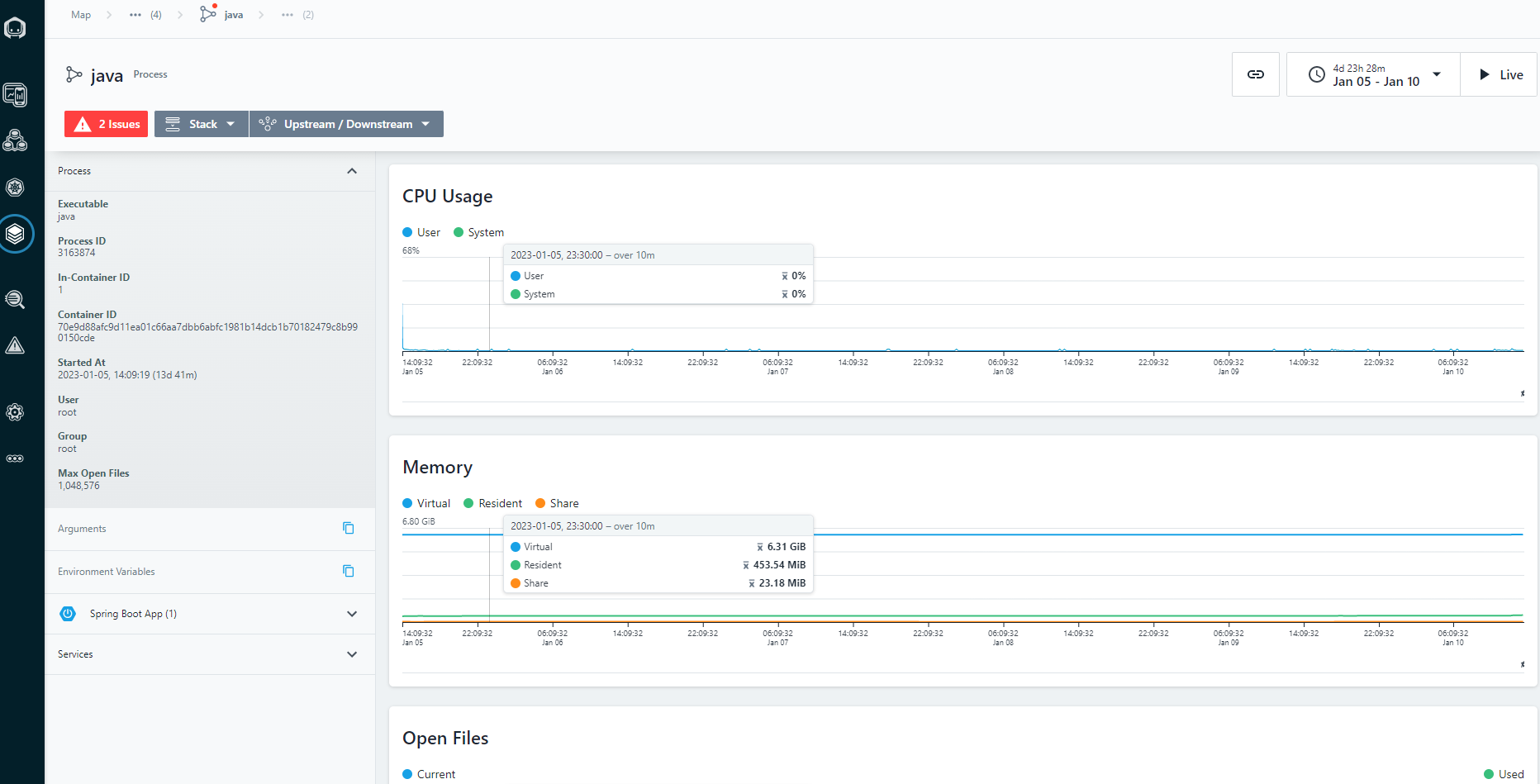
The issue doesn't happen that often but enought to be noticed. The service is not doing anything crazy at the moment when it's happening, just normal load. Also, interesting fact that memory doesn't gradually increase, on the contrary - it's like a sudden explosion.
I also did some deep analysis on what apps are doing at the time of mem explosion - all seem normal to be normal which is why I don't think it's some problem or memory leak in the code. Plus same behaviour happens across different services that are not connected with each other in almost any way. Also, i most of the cases after restarting service proceeding with the work where it was left off. Which is why I'm leaning towards the idea that it's some kind of Framework or Software problem.
More on the setup:
- Spring Boot (2.4.x - 2.5.x). Different stacks(Web and WebFlux) and dependencies (Spring Cloud, Spring Kafka, ElasticSearch, Postgres, etc) are used accross microservices.
- Java 11 (latest OpenJDK image)
- The apps are running on one of the newest versions of Kubernetes cluster(AKS).
- Before we had no resource limits implemented for microservices. So in case of an incident, we had an infinite memory allocation until it eats all of the memory of K8S node which forces everything to get down & restart. Currently we have resource limits for pods implemented to avoid that behaviour.
Questions:
- I'm wondering if it's a JVM/Spring issue / memory leak. Maybe someone had a similar experience?
- Are there any tools / approaches you can recommend to take a snapshot of the pod before it's getting killed to have an ability to analyze that later?
CodePudding user response:
We were able to catch metrics at the time when it's happening. Turned out, that memory limits were misconfigured in helm charts and default values were taken by JVM. This leaded to situtation when JVM had a lot (around 3GB) memory allocated but only used some (150MB). So our K8s node was experiencing some memory starvation at the time when it was running lots of in the mode like that mode.
And yes, Instana turned out to be quite helpful tool to debug that. See metrics listed below: