i am trying to use normalize function to convert json to data frame using json_normalize. This is the json i am working with
data = {
"Parent":
[
{
"Attributes":
[
{
"Values": [{
"Month": "Jan",
"Value": "100"
}],
"Id": "90",
"CustId": "3"
},
{
"Values": [{
"Month": "Jan",
"Value": "101"
}],
"Id": "88"
},
{
"Values": [{
"Month": "Jan",
"Value": "102"
}],
"Id": "89"
}
],
"DId": "1234"
},
{
"Attributes":
[
{
"Values": [{
"Month": "Jan",
"Value": "200"
}],
"Id": "90",
"CustId": "3"
},
{
"Values": [{
"Month": "Jan",
"Value": "201"
}],
"Id": "88"
},
{
"Values": [{
"Month": "Jan",
"Value": "202"
}],
"Id": "89"
}
],
"DId": "5678"
}
]
}
and this is what i have tried
print(type(data))
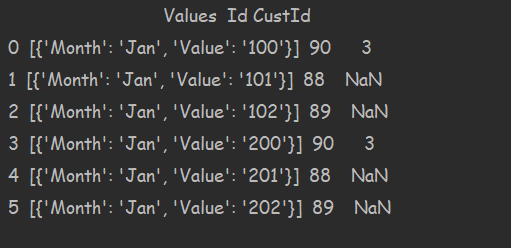
result = pd.json_normalize(data, record_path=['Parent',['Attributes']], max_level=2)
print(result.to_string())
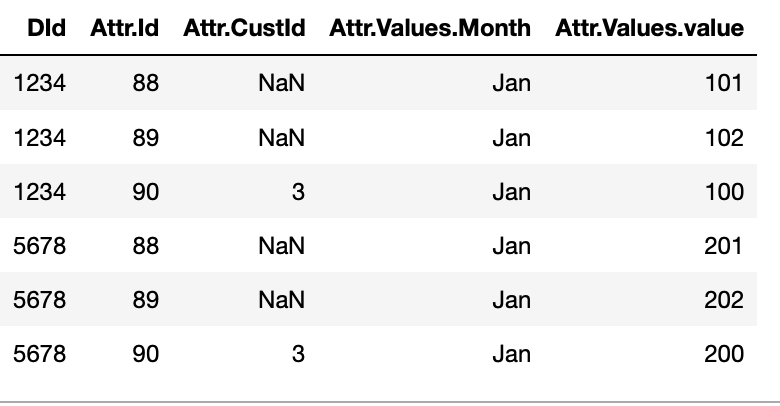
And it gave the result , but it is missing the DId and values column is still a list of dict
And this is what i want to achieve
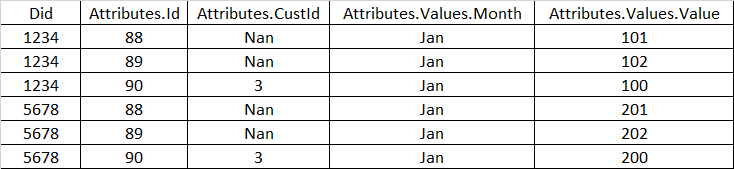
Any guidance how to accomplish it would be highly appreciated.
CodePudding user response:
You can specify meta data (data above the record_path) via the meta keyword argument (in combination with errors='ignore' for meta data that isn't necessarily there, like CustId). For instance
result = pd.json_normalize(
data,
record_path=['Parent', 'Attributes', 'Values'],
meta=[
['Attributes', 'DId'],
['Parent', 'Attributes', 'Id'],
['Parent', 'Attributes', 'CustId']
],
errors='ignore'
)
results in
Month Value Attributes.DId Parent.Attributes.Id Parent.Attributes.CustId
0 Jan 100 1234 90 3
1 Jan 101 1234 88 NaN
2 Jan 102 1234 89 NaN
3 Jan 200 5678 90 3
4 Jan 201 5678 88 NaN
5 Jan 202 5678 89 NaN
CodePudding user response:
this is one way of achieving this, I think step1 and step2 can be combined together which needs some more insight on pd.json_normalize
#step1
df1=pd.json_normalize(
data['Parent'],["Attributes","Values"]
)
#step2
df2=pd.json_normalize(
data['Parent'],"Attributes","DId",
)
df2=df2.drop(['Values'], axis=1)
result=df2.join(df1).reindex(['DId','Id','CustId','Month','Value'], axis=1)\
.sort_values(by=['DId','Id']) \
.rename(columns={'Id':'Attr.Id','CustId':'Attr.CustId','Month':'Attr.Values.Month',
'Value':'Attr.Values.value'
})
result: