Say I have following dataframe:
d = {'col1': ["8","8","8","8","8","2","2","2","2","3","3"], 'col2': ['a', 'b','b','b','b','a','b','a','a','a','b'],
'col3': ['m', 'n','z','b','a','ac','b1','ad','a1','a','b1'],'col4': ['m', 'n','z','b1','a','ac1','b31','a1d','3a1','a3','b1']}
test = pd.DataFrame(data=d)
In order to sort each grouped item with count, I could do the following:
test.groupby(["col1",'col2'])['col4'].count().reset_index(name="count").sort_values(["col1","count"],ascending=[True,False]).
It returns this table:
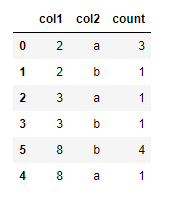
However, I want the group with 8 in col1 to be the first item because this particular group has the highest count (i.e., 4).
How do I achieve this?
Edit: This is the expected output:
col1 col2 count
8 b 4
8 a 1
2 a 3
2 b 1
3 a 1
3 b 1
CodePudding user response:
The expected output is unclear, but assuming you want to sort the rows within each group by decreasing orders of count, and also the groups with each other by decreasing order of the max (or total) count.
(test.groupby(["col1",'col2'])['col4'].count()
.reset_index(name="count")
# using the max count per group, for the total use transform('sum')
.assign(maxcount=lambda d: d.groupby('col1')['count'].transform('max'))
.sort_values(['maxcount', 'count'], ascending=False)
.drop(columns='maxcount')
)
Output:
col1 col2 count
5 8 b 4
4 8 a 1
0 2 a 3
1 2 b 1
2 3 a 1
3 3 b 1
CodePudding user response:
You need to fix your sorting in that case. Your description is a bit unclear, therefore a general guideline to solving your problem.
Sort_values sorts from left to right, where the first item defines the order of the group and following items define the order, if the first item is equal.
Therefore, select the order of your columns in which you would like to sort and set the ascending parameter correctly.