I have a PySpark DataFrame with columns 'Country' and 'Continent'. In several records, value of 'Continent' is missing. However, there are records containing 'Continent' for the same country (Examples of "Italy" and "China" in the sample dataset below).
# Prepare Data
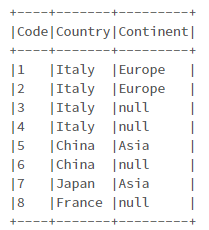
data = [
(1, "Italy", "Europe"),
(2, "Italy", "Europe"),
(3, "Italy", None),
(4, "Italy", None),
(5, "China", "Asia"),
(6, "China", None),
(7, "Japan", "Asia"),
(8, "France", None),
]
# Create DataFrame
columns = ["Code", "Country", "Continent"]
df = spark.createDataFrame(data=data, schema=columns)
df.show(truncate=False)
For records whose 'Continent' is Null, I want to:
Look for any record of the same country whose 'Continent' is not Null
Get the value of 'Continent' and fill in the Null value
The expected output will be like:
| Code | Country | Continent |
|---|---|---|
| 1 | 'Italy' | 'Europe' |
| 2 | 'Italy' | 'Europe' |
| 3 | 'Italy' | 'Europe' |
| 4 | 'Italy' | 'Europe' |
| 5 | 'China' | 'Asia' |
| 6 | 'China' | 'Asia' |
| 7 | 'Japan' | 'Asia' |
| 8 | 'France' | Null |
Any idea how to do that?
CodePudding user response:
Here is one of the solution. Assuming there is only 1 distinct Continent value in each country, you can use the max() within each country partition:
df2 = df.withColumn(
"Continent",
func.when(
func.col("Continent").isNull(),
func.max("Continent").over(Window.partitionBy(func.col("Country"))),
).otherwise(func.col("Continent")),
).orderBy("code")
df2.show(truncate=False)
---- ------- ---------
|Code|Country|Continent|
---- ------- ---------
|1 |Italy |Europe |
|2 |Italy |Europe |
|3 |Italy |Europe |
|4 |Italy |Europe |
|5 |China |Asia |
|6 |China |Asia |
|7 |Japan |Asia |
|8 |France |null |
---- ------- ---------
Or you can create a smaller "reference" dataframe and do the broadcasting join back to the main dataframe.
CodePudding user response:
Another solution, same result :
from pyspark.sql import functions as F, Window
df.withColumn(
"continent",
F.coalesce(
F.col("continent"),
F.first("continent").over(Window.partitionBy("country")),
),
).show()
---- ------- ---------
|Code|Country|continent|
---- ------- ---------
| 5| China| Asia|
| 6| China| Asia|
| 8| France| null|
| 1| Italy| Europe|
| 2| Italy| Europe|
| 3| Italy| Europe|
| 4| Italy| Europe|
| 7| Japan| Asia|
---- ------- ---------