I have a dataset that looks like this:
df = pd.DataFrame({
'Vintage': ['2016Q1','2016Q1', '2016Q2','2016Q3','2016Q4','2016Q1', '2016Q2','2016Q2','2016Q2','2016Q3','2016Q4'],
'Model': ['A','A','A','A','A','B','B','B','B','B','B',],
'Count': [1,1,1,1,1,1,1,1,1,1,1],
'Case':[0,1,1,0,1,1,0,0,1,1,0],
})
Vintage Model Count Case
0 2016Q1 A 1 0
1 2016Q1 A 1 1
2 2016Q2 A 1 1
3 2016Q3 A 1 0
4 2016Q4 A 1 1
5 2016Q1 B 1 1
6 2016Q2 B 1 0
7 2016Q2 B 1 0
8 2016Q2 B 1 1
9 2016Q3 B 1 1
10 2016Q4 B 1 0
What I need to do is:
- Plot grouped bar chart, where
vintageis the groups andmodelis the hue/color - Two line plots in the same chart that show the percentage of
caseovercount, aka plot the division of case over count for each model and vintage.
I figured out how to do the first task with a pivot table but haven't been able to add the percentage from the same pivot.
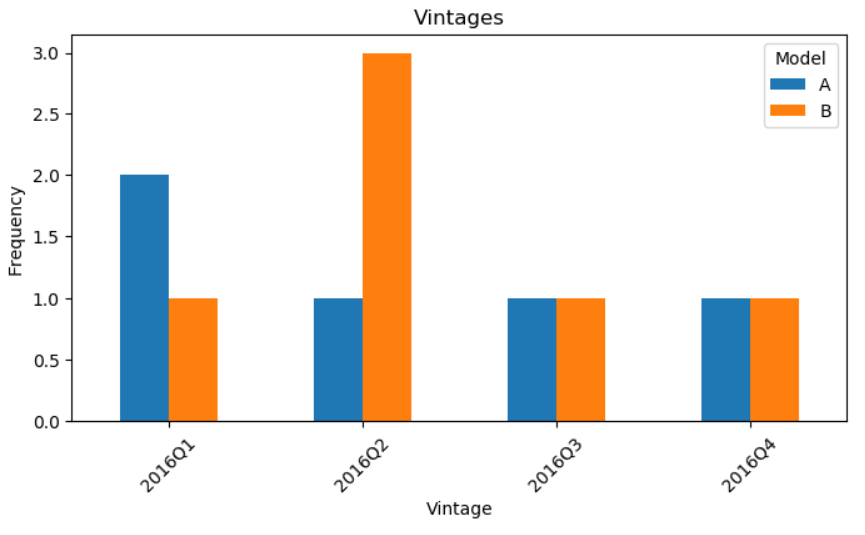
This is the solution for point 1:
dfp = df.pivot_table(index='vintage', columns='model', values='count', aggfunc='sum')
dfp.plot(kind='bar', figsize=(8, 4), rot=45, ylabel='Frequency', title="Vintages")
I tried dividing between columns in the pivot table but it's not the right format to plot.
How can I do the percentage calculation and line plots so without creating a different table?
Could the whole task be done with groupby instead? (as I find it easier to use in general)
CodePudding user response:
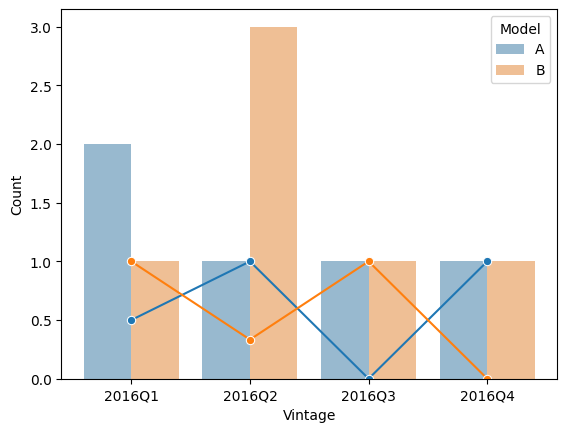
Here's a solution using the seaborn plotting library, not sure if it's ok for you to use it for your problem
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.DataFrame({
'Vintage': ['2016Q1','2016Q1', '2016Q2','2016Q3','2016Q4','2016Q1', '2016Q2','2016Q2','2016Q2','2016Q3','2016Q4'],
'Model': ['A','A','A','A','A','B','B','B','B','B','B',],
'Count': [1,1,1,1,1,1,1,1,1,1,1],
'Case':[0,1,1,0,1,1,0,0,1,1,0],
})
agg_df = df.groupby(['Vintage','Model']).sum().reset_index()
agg_df['Fraction'] = agg_df['Case']/agg_df['Count']
sns.barplot(
x = 'Vintage',
y = 'Count',
hue = 'Model',
alpha = 0.5,
data = agg_df,
)
sns.lineplot(
x = 'Vintage',
y = 'Fraction',
hue = 'Model',
marker = 'o',
legend = False,
data = agg_df,
)
plt.show()
plt.close()
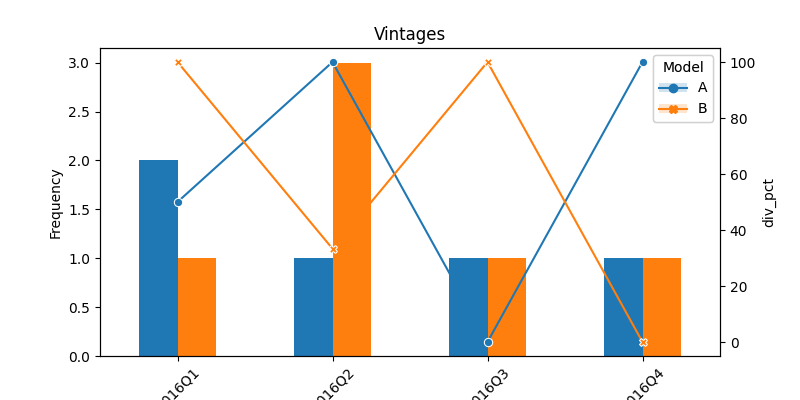
CodePudding user response:
IIUC you want the lines to be drawn on the same plot. I'd recommend creating a new y-axis after computing the division from the original df. Then you can plot the lines with seaborn:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.DataFrame({
'Vintage': ['2016Q1','2016Q1', '2016Q2','2016Q3','2016Q4','2016Q1', '2016Q2','2016Q2','2016Q2','2016Q3','2016Q4'],
'Model': ['A','A','A','A','A','B','B','B','B','B','B',],
'Count': [1,1,1,1,1,1,1,1,1,1,1],
'Case':[0,1,1,0,1,1,0,0,1,1,0],
})
dfp = df.pivot_table(index='Vintage', columns='Model', values='Count', aggfunc='sum')
ax1 = dfp.plot(kind='bar', figsize=(8, 4), rot=45, ylabel='Frequency', title="Vintages")
dfd = df.groupby(["Vintage", "Model"]).sum() \
.assign(div_pct=lambda x:100*x["Case"]/x["Count"]) \
.reset_index()
ax2 = ax1.twinx() # creating a second y axis
sns.lineplot(data=dfd, x="Vintage", y="div_pct", hue="Model", style="Model", ax=ax2, markers=True, dashes=False)
plt.show()
Output: