I have found few good solutions but they do not work with the latest version of spark. Like this one!
from pyspark.sql import Row
df = sc.parallelize([Row(visit_dts='5/1/2018 3:48:14 PM')]).toDF()
import pyspark.sql.functions as f
web = df.withColumn("web_datetime", f.from_unixtime(f.unix_timestamp("visit_dts",'MM/dd/yyyy hh:mm:ss aa'),'MM/dd/yyyy HH:mm:ss'))
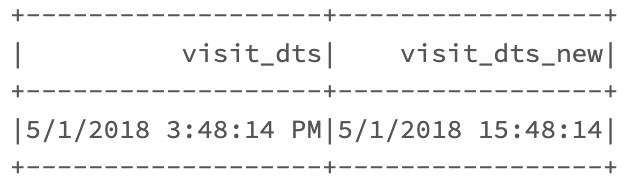
Expecting:
web.show()
------------------- -------------------
| visit_dts| web_datetime|
------------------- -------------------
|5/1/2018 3:48:14 PM|05/01/2018 15:48:14|
------------------- -------------------
Actual output:
org.apache.spark.SparkUpgradeException: You may get a different result due to the upgrading of Spark 3.0: Fail to recognize 'EEE MMM dd HH:mm:ss zzz yyyy' pattern in the DateTimeFormatter.
CodePudding user response:
Use "M" instead of "MM" for numbers without padding i.e. without 0 prefixes and "a" instead of "aa" for Spark 3 , see 
Output: