I would like to get the table data from a certain website to play with the data statistically, however I'm failing on the interactive button which selects each sector from the linked race. How can I iterate through the button list and store each table in a list or a resulting df? An explanation would be appreciated so I can learn how this works. So far I can only extract the text from the first page:
site = "http://live.fis-ski.com/cc-4023/results-pda.htm"
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver', options= options)
driver.get(site)
try:
main = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'tab1'))
)
print(main.text)
result = main.text
except:
driver.quit()
This gives me just a list of the main page with each sector.
Thanks!
CodePudding user response:
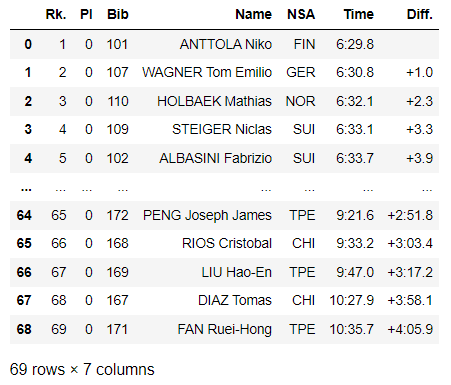
With Select you can select the value of the dropdown and change the race type. With .get_attribute('innerText') you can get the values of the hidden rows too (.text doesn't work for them). With pandas you can store data in a dataframe, eventually saving it to csv.
from selenium.webdriver.support.ui import Select
import pandas as pd
... import other libraries ...
... start chromedriver and load site ...
dropdown = WebDriverWait(driver, 9).until(EC.element_to_be_clickable((By.ID, 'int1')))
races = dropdown.text.strip().split('\n')
data = dict.fromkeys(races)
for race in races:
print(race, end='')
Select(dropdown).select_by_visible_text(race)
time.sleep(1)
rows = driver.find_elements(By.XPATH, "//div[@id='resultpoint1']/ul/li")
print(f': {len(rows)} athletes')
table = []
for row in rows:
columns = row.find_elements(By.XPATH, "./div")
table.append([c.get_attribute('innerText') for c in columns])
column_names = [c.text for c in driver.find_elements(By.CSS_SELECTOR, '#result1 .tableheader div:not([class*=hidden])')]
data[race] = pd.DataFrame(table, columns=column_names)
# data[race].to_csv(race '.csv', index=False)
Output
Start list: 72 athletes
600 m: 69 athletes
1200 m: 69 athletes
2200 m: 69 athletes
2500 m: 69 athletes
4000 m: 69 athletes
...
Each table is saved in a dict, for example data['2500 m'] prints the following