This question is really confusing me. They didn't provide enough details of it. Whatever they have provided I have written below.
- job_id: unique identifier of jobs
- actor_id: unique identifier of actor
- event: decision/skip/transfer
- language: language of the content
- time_spent: time spent to review the job in seconds
- org: organization of the actor
- ds: date in the yyyy/mm/dd format. It is stored in the form of text and we use presto to run. no need for date function
CREATE TABLE job_data
(
ds DATE,
job_id INT NOT NULL,
actor_id INT NOT NULL,
event VARCHAR(15) NOT NULL,
language VARCHAR(15) NOT NULL,
time_spent INT NOT NULL,
org CHAR(2)
);
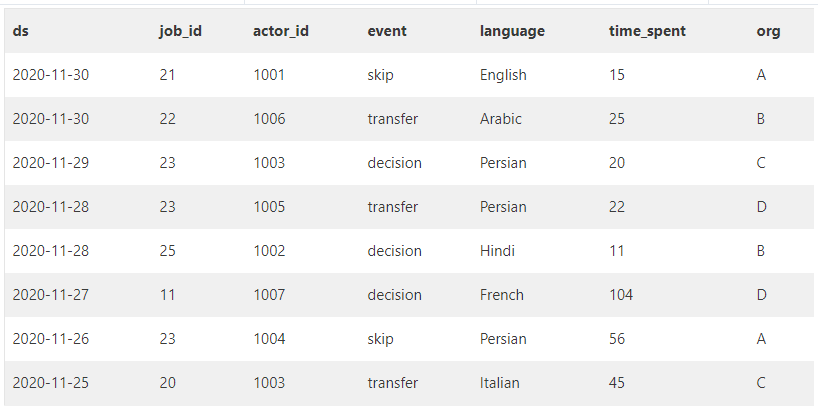
INSERT INTO job_data (ds, job_id, actor_id, event, language, time_spent, org)
VALUES ('2020-11-30', 21, 1001, 'skip', 'English', 15, 'A'),
('2020-11-30', 22, 1006, 'transfer', 'Arabic', 25, 'B'),
('2020-11-29', 23, 1003, 'decision', 'Persian', 20, 'C'),
('2020-11-28', 23, 1005,'transfer', 'Persian', 22, 'D'),
('2020-11-28', 25, 1002, 'decision', 'Hindi', 11, 'B'),
('2020-11-27', 11, 1007, 'decision', 'French', 104, 'D'),
('2020-11-26', 23, 1004, 'skip', 'Persian', 56, 'A'),
('2020-11-25', 20, 1003, 'transfer', 'Italian', 45, 'C');
Below is the data. Points to be considered :
What does the event mean? What to consider for reviewing?
And here's the query I've tried:
SELECT ds, COUNT(*)/24 AS no_of_job
FROM job_data
WHERE ds BETWEEN '2020-11-01' AND '2020-11-30'
GROUP BY ds;
CodePudding user response:
Check below approach if it is what you are looking for.
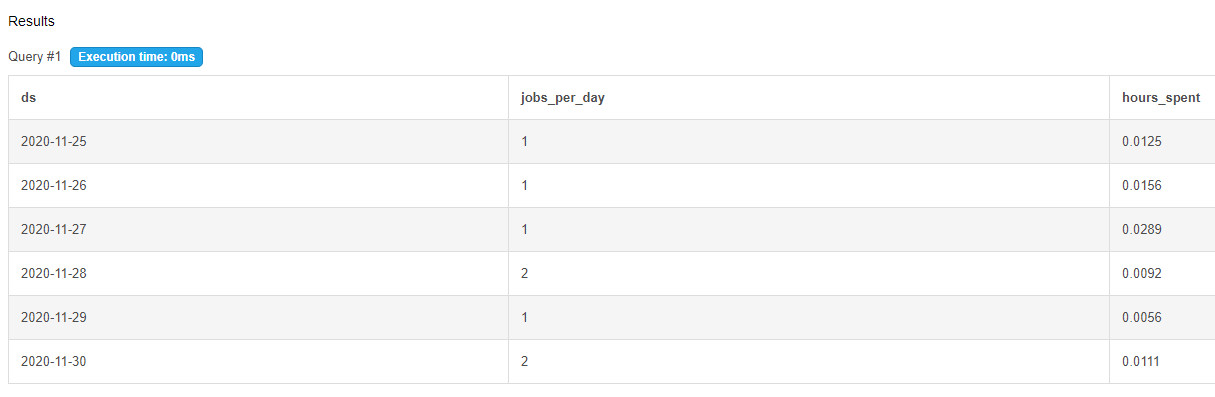
select ds,count(job_id) as jobs_per_day, sum(time_spent)/3600 as hours_spent
from job_data
where ds >='2020-11-01' and ds <='2020-11-30'
group by ds ;
Demo MySQL 5.6: