I'd like to uniquely identify groups of rows that use the same grouping.
For example, if we imagine some epos data, I'd like to identify the customers that bought the exact same combination of items, relating them all to a definition of the set (see example below).
This feels like a window function problem, but I'm still trying to figure out how to use them to identify a unique combination of rows, rather than partitioning by a customer or item.
In the below example, I would like to identify all occurrences of only red and blue as set 1, green and yellow as set 2 etc. the number of rows/values in the mapping is unbounded so pivoting and then grouping/joining would not be suitable.
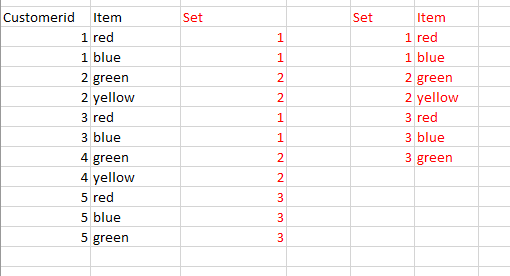
What would be the easiest way to go about this?
CodePudding user response:
The simplest method is actually string aggregation. In Standard SQL, this looks like:
select items,
listagg(customerid, ',') within group (order by customerid) as customerids,
row_number() over (order by items) as group_id
from (select customerid,
listagg(item, ',') within group (order by item) as items
from t
) c
group by items;
The result set is not exactly what you specify, because the ids are combined together in a single row.
EDIT:
In SQL Server, the syntax would use string_agg():
select items,
string_agg(customerid, ',') within group (order by customerid) as customerids,
row_number() over (order by items) as group_id
from (select customerid,
string_agg(item, ',') within group (order by item) as items
from t
) c
group by items;