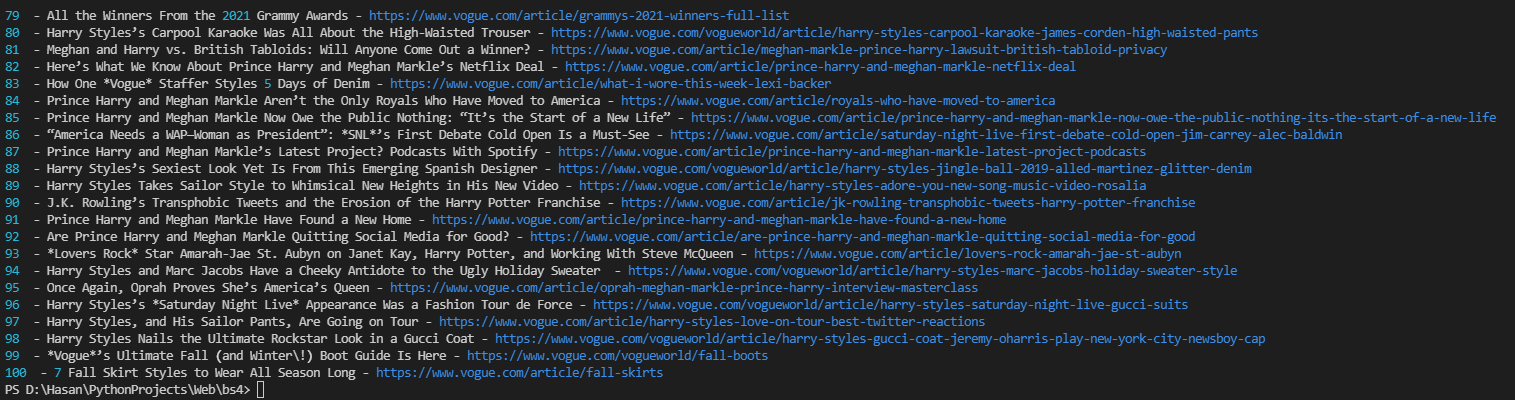
I am trying to scrape article titles and links from Vogue with a site search keyword. I can't get the top 100 results because the "Show More" button obscures them. I've gotten around this before by using the changing URL, but Vogue's URL does not change to include the page number, result number, etc.
import requests
from bs4 import BeautifulSoup as bs
url = 'https://www.vogue.com/search?q=HARRY STYLES&sort=score desc'
r = requests.get(url)
soup = bs(r.content, 'html')
links = soup.find_all('a', {'class':"summary-item-tracking__hed-link summary-item__hed-link"})
titles = soup.find_all('h2', {'class':"summary-item__hed"})
res = []
for i in range(len(titles)):
entry = {'Title': titles[i].text.strip(), 'Link': 'https://www.vogue.com' links[i]['href'].strip()}
res.append(entry)
Any tips on how to scrape the data past the "Show More" button?
CodePudding user response:
You can inspect the requests on the website using your browser's web developer tools to find out if its making a specific request for data of your interest. In this case, the website is loading more info by making GET requests to an URL like this:
https://www.vogue.com/search?q=HARRY STYLES&page=<page_number>&sort=score desc&format=json
Where <page_number> is > 1 as page 1 is what you see by default when you visit the website.
Assuming you can/will request a limited amount of pages and as the data format is JSON, you will have to transform it to a dict() or other data structure to extract the data you want. Specifically targeting the "search.items" key of the JSON object since it contains an array of data of the articles for the requested page.
Then, the "Title" would be search.items[i].source.hed and you could assemble the link with search.items[i].url.
As a tip, I think is a good practice to try to see how the website works manually and then attempt to automate the process. If you want to request data to that URL, make sure to include some delay between requests so you don't get kicked out or blocked.
CodePudding user response:
You have to examine the Network from developer tools. Then you have to determine how to website requests the data. You can see the request and the response in the screenshot.
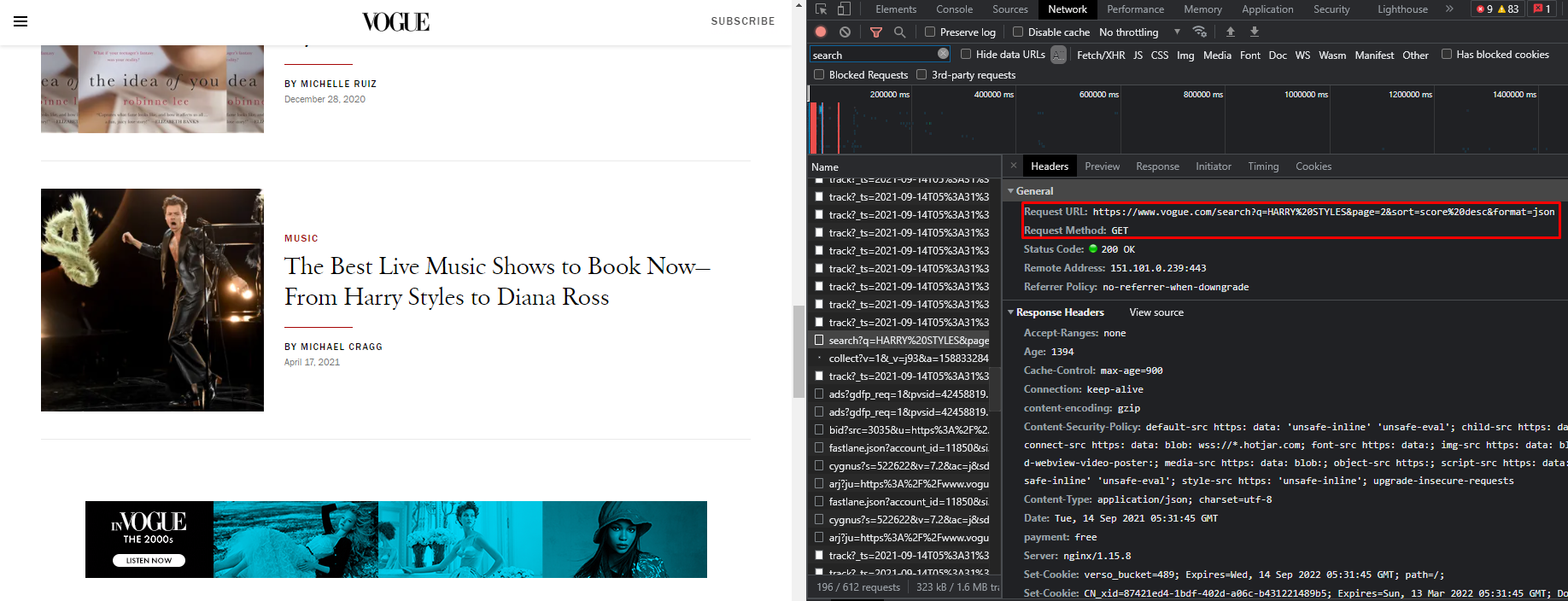
The website is using page parameter as you see.
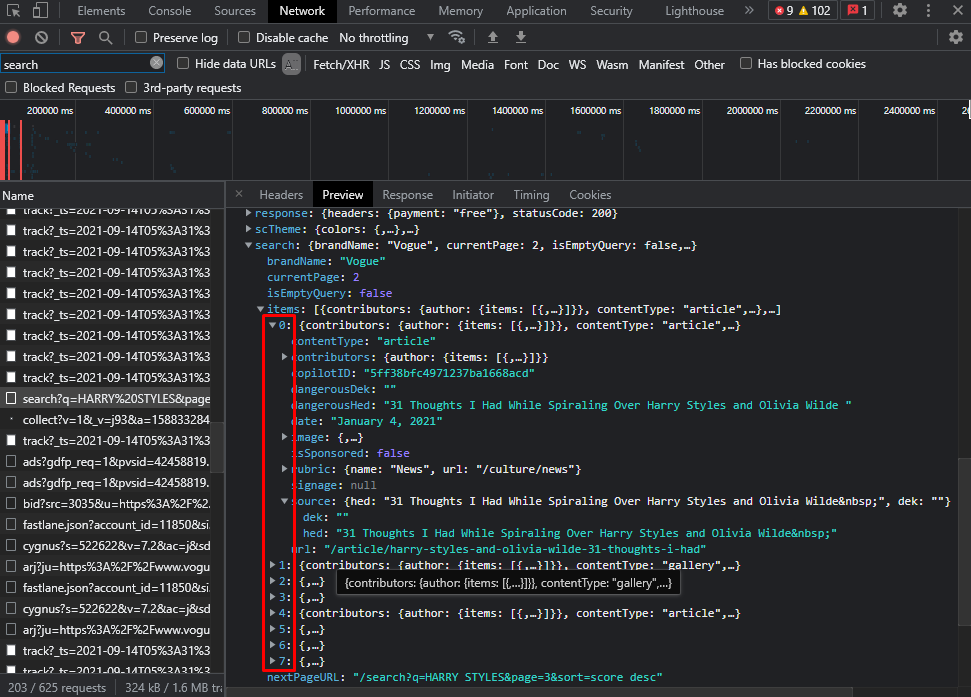
Each page has 8 titles. So you have to use the loop to get 100 titles.
Code:
import cloudscraper,json,html
counter=1
for i in range(1,14):
url = f'https://www.vogue.com/search?q=HARRY STYLES&page={i}&sort=score desc&format=json'
scraper = cloudscraper.create_scraper(browser={'browser': 'firefox','platform': 'windows','mobile': False},delay=10)
byte_data = scraper.get(url).content
json_data = json.loads(byte_data)
for j in range(0,8):
title_url = 'https://www.vogue.com' (html.unescape(json_data['search']['items'][j]['url']))
t = html.unescape(json_data['search']['items'][j]['source']['hed'])
print(counter," - " t ' - ' title_url)
if (counter == 100):
break
counter = counter 1
Output: