Table 1
df1 = pd.DataFrame({'df1_id':['1','2','3'],'col1':["a","b","c"],'col2':["d","e","f"]})
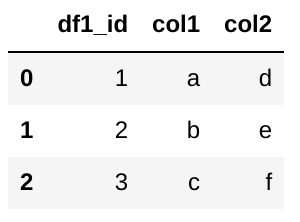
Table 2
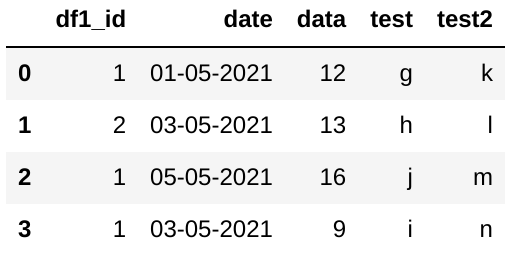
df2 = pd.DataFrame({'df1_id':['1','2','1','1'],'date':['01-05-2021','03-05-2021','05-05-2021','03-05-2021'],'data':[12,13,16,9],'test':['g','h','j','i'],'test2':['k','l','m','n']})
Result Table

Brief Explanation on how the Result table needs to be created:
I have two data frames and I want to merge them based on a
df_id. But thedatecolumn from second table should be transposed into the resultant table.The date columns for the result table will be a range between the min date and max date from the second table
The column values for the dates in the result table will be from the
datacolumn of the second table.Also the
testcolumn from the second table will only take its value of the latest date for the result table
I hope this is clear. Any suggestion or help regarding this will be greatly appreciated.
I have tried using pivot on the second table and then trying to merge the pivoted second table df1 but its not working. I do not know how to get only one row for the latest value of test.
Note: I am trying to solve this problem using vectorization and do not want to serially parse through each row
CodePudding user response:
You need to pivot your df2 into two separate table as we need data and test values and then merge both resulting pivot table with df1
df1 = pd.DataFrame({'df1_id':['1','2','3'],'col1':["a","b","c"],'col2':["d","e","f"]})
df2 = pd.DataFrame({'df1_id':['1','2','1','1'],'date':['01-05-2021','03-05-2021','03-05-2021','05-05-2021'],'data':[12,13,9,16],'test':['g','h','i','j']})
test_piv = df2.pivot(index=['df1_id'],columns=['date'],values=['test'])
data_piv = df2.pivot(index=['df1_id'],columns=['date'],values=['data'])
max_test = test_piv['test'].ffill(axis=1).iloc[:,-1].rename('test')
final = df1.merge(data_piv['data'],left_on=df1.df1_id, right_index=True, how='left')
final = final.merge(max_test,left_on=df1.df1_id, right_index=True, how='left')
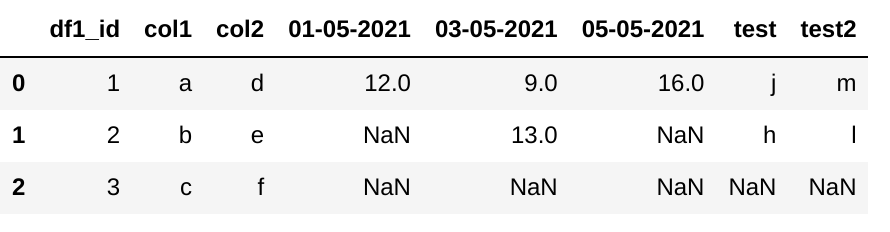
and hence your resulting final dataframe as below
| | df1_id | col1 | col2 | 01-05-2021 | 03-05-2021 | 05-05-2021 | test |
|---:|---------:|:-------|:-------|-------------:|-------------:|-------------:|:-------|
| 0 | 1 | a | d | 12 | 9 | 16 | j |
| 1 | 2 | b | e | nan | 13 | nan | h |
| 2 | 3 | c | f | nan | nan | nan | nan |
CodePudding user response:
Here is the solution for the question:
I first sort
df2based ofdf1_idanddateto ensure that table entries are in order.Then I drop duplicates based on
df_idand select the last row to ensure I have the latest values fortestandtest2Then I pivot
df2to get the correspondingdateas column anddataas its valueThen I merge the table with
df2_pivotedto combine the latest values oftestandtest2Then I merge with
df1to get the resultant table
df1 = pd.DataFrame({'df1_id':['1','2','3'],'col1':["a","b","c"],'col2':["d","e","f"]})
df2 = pd.DataFrame({'df1_id':['1','2','1','1'],'date':['01-05-2021','03-05-2021','05-05-2021','03-05-2021'],'data':[12,13,16,9],'test':['g','h','j','i'],'test2':['k','l','m','n']})
df2=df2.sort_values(by=['df1_id','date'])
df2_latest_vals = df2.drop_duplicates(subset=['df1_id'],keep='last')
df2_pivoted = df2.pivot_table(index=['df1_id'],columns=['date'],values=['data'])
df2_pivoted = df2_pivoted.droplevel(0,axis=1).reset_index()
df2_pivoted = pd.merge(df2_pivoted,df2_latest_vals,on='df1_id')
df2_pivoted = df2_pivoted.drop(columns=['date','data'])
result = pd.merge(df1,df2_pivoted,on='df1_id',how='left')
result
Note: I have not been able to figure out how to get the entire date range between 01-05-2021 and 05-05-2021 and show the empty values as NaN. If anyone can help please edit the answer