I have the following dataframe:
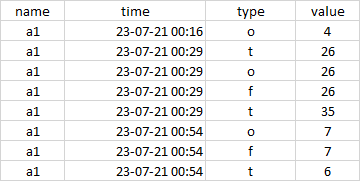
Different 'type' can occur at the same 'time', but the need is to only get the 'type' and 'value' based on the following conditions:
- priority 1: the type importance is so as t>o>f
- priority 2: highest value to be considered from value column
I have tried using groupby and dictionary with:
grp = merged_df.groupby(['name','time'],as_index=False)[['type','value']].apply(lambda x: dict(x.values.tolist()))
This gives such an output:

Is there any way to get the optimum key value pair based on the above two rules so that the output can be:
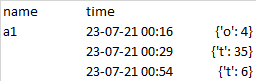
The above is one method I tried and thats why the question is about optimum key value pair from a dictionary. However, any other more elegant method would be also fine.
The end result should be:
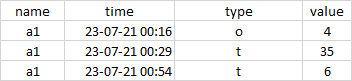
CodePudding user response:
The following answer might not be that elegant since: 1. it need you to create a dictionary beforehand, where you map priority 1 (t > o > f) and 2. bypasses working with dictionaries but should get the job done:
First, create a dictionary according to priority 1 and use it to create a new mapped column based on 'type':
prio_dic = {'t':'3', 'o':'2', 'f':'1'}
data["coded_type"] = data["type"].map(prio_dic)
Finally, sort the values according first using new column 'coded_type' and second with 'value', group by 'name' and 'time' as you did and get the first element for each group:
res = data.sort_values(['coded_type', 'value', ], ascending=False).groupby(['name', 'time'], as_index=False).first()
Unfortunately, this recquires the extra step of deleting the new column:
res.drop('coded_type', axis=1)