I have a pandas dataframe df which looks as follows:
Unnamed: 0 Characters Length Characters Split A B C D Names with common 3-letters
0 FROKDUWJU 9 [FRO, KDU, WJU] FRO KDU WJU NaN
1 IDJWPZSUR 9 [IDJ, WPZ, SUR] IDJ WPZ SUR NaN
2 UCFURKIRODCQ 12 [UCF, URK, IRO, DCQ] UCF URK IRO DCQ
3 ORI 3 [ORI] ORI NaN NaN NaN
4 PROIRKIQARTIBPO 15 [PRO, IRK, IQA, RTI, BPO] PRO IRK IQA RTI
5 QAZWREDCQIBR 12 [QAZ, WRE, DCQ, IBR] QAZ WRE DCQ IBR
6 PLPRUFSWURKI 12 [PLP, RUF, SWU, RKI] PLP RUF SWU RKI
7 FROIEUSKIKIR 12 [FRO, IEU, SKI, KIR] FRO IEU SKI KIR
8 ORIUWJZSRFRO 12 [ORI, UWJ, ZSR, FRO] ORI UWJ ZSR FRO
9 URKIFJVUR 9 [URK, IFJ, VUR] URK IFJ VUR NaN
10 RUFOFR 6 [RUF, OFR] RUF OFR NaN NaN
11 IEU 3 [IEU] IEU NaN NaN NaN
12 PIMIEU 6 [PIM, IEU] PIM IEU NaN NaN
In the last column, Names with common 3-letters, I'd like to have a list of all the names from first column which have common 3-letters set in their names. For example, in the first row, I'd like to have a list of all the names which have FRO, KRU and WJU in their names. These 3-letter split of names could also be found in "Characters Split" or A,B, C, and D columns for reference.
To talk in a stepwise manner, I need to scan whether the 3-letter set present in a name in a given row is also present in any name in rest of the rows. And if it is present, I need to add the corresponding name of the other row as a list in "Names with common 3-letters" column. As an example, in the screenshot attached, in column C, the yellow highlighted cells have the names that have common 3-letter set with the name in same row. 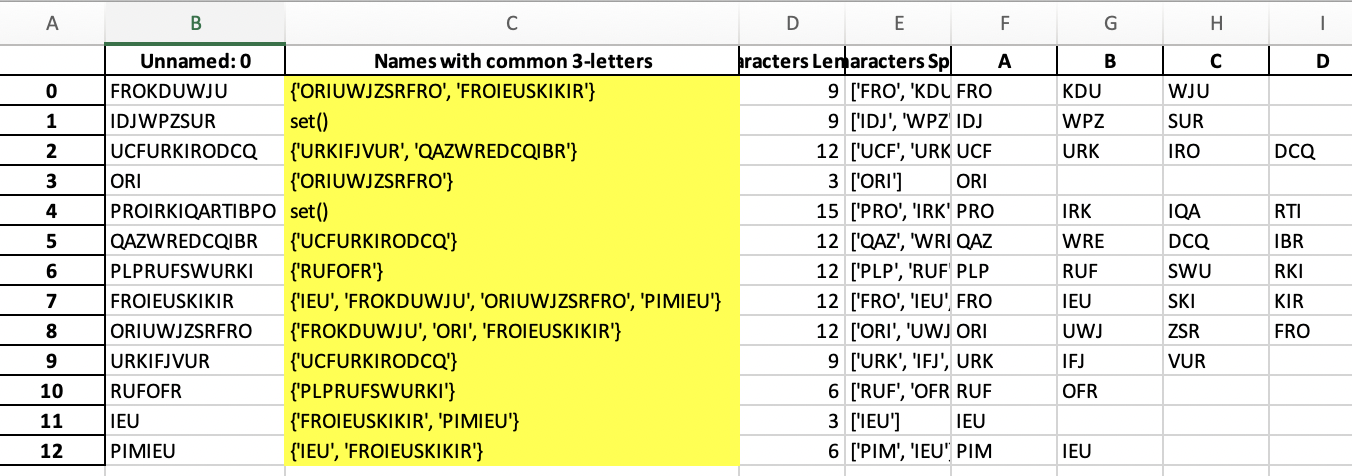
What would be the appropriate way to accomplish this? Should I use a function or a loop-statement?
Note: df.to_dict() looks as follows:
{'Unnamed: 0': {0: 'FROKDUWJU',
1: 'IDJWPZSUR',
2: 'UCFURKIRODCQ',
3: 'ORI',
4: 'PROIRKIQARTIBPO',
5: 'QAZWREDCQIBR',
6: 'PLPRUFSWURKI',
7: 'FROIEUSKIKIR',
8: 'ORIUWJZSRFRO',
9: 'URKIFJVUR',
10: 'RUFOFR',
11: 'IEU',
12: 'PIMIEU'},
'Characters Length': {0: 9,
1: 9,
2: 12,
3: 3,
4: 15,
5: 12,
6: 12,
7: 12,
8: 12,
9: 9,
10: 6,
11: 3,
12: 6},
'Characters Split': {0: ['FRO', 'KDU', 'WJU'],
1: ['IDJ', 'WPZ', 'SUR'],
2: ['UCF', 'URK', 'IRO', 'DCQ'],
3: ['ORI'],
4: ['PRO', 'IRK', 'IQA', 'RTI', 'BPO'],
5: ['QAZ', 'WRE', 'DCQ', 'IBR'],
6: ['PLP', 'RUF', 'SWU', 'RKI'],
7: ['FRO', 'IEU', 'SKI', 'KIR'],
8: ['ORI', 'UWJ', 'ZSR', 'FRO'],
9: ['URK', 'IFJ', 'VUR'],
10: ['RUF', 'OFR'],
11: ['IEU'],
12: ['PIM', 'IEU']},
'A': {0: 'FRO',
1: 'IDJ',
2: 'UCF',
3: 'ORI',
4: 'PRO',
5: 'QAZ',
6: 'PLP',
7: 'FRO',
8: 'ORI',
9: 'URK',
10: 'RUF',
11: 'IEU',
12: 'PIM'},
'B': {0: 'KDU',
1: 'WPZ',
2: 'URK',
3: nan,
4: 'IRK',
5: 'WRE',
6: 'RUF',
7: 'IEU',
8: 'UWJ',
9: 'IFJ',
10: 'OFR',
11: nan,
12: 'IEU'},
'C': {0: 'WJU',
1: 'SUR',
2: 'IRO',
3: nan,
4: 'IQA',
5: 'DCQ',
6: 'SWU',
7: 'SKI',
8: 'ZSR',
9: 'VUR',
10: nan,
11: nan,
12: nan},
'D': {0: nan,
1: nan,
2: 'DCQ',
3: nan,
4: 'RTI',
5: 'IBR',
6: 'RKI',
7: 'KIR',
8: 'FRO',
9: nan,
10: nan,
11: nan,
12: nan},
'Names with common 3-letters': {0: '',
1: '',
2: '',
3: '',
4: '',
5: '',
6: '',
7: '',
8: '',
9: '',
10: '',
11: '',
12: ''}}
CodePudding user response:
There may be a quicker way to search and create the lists, but this works:
# create a different temporary, column (you can't search the Characters Split column directly as the 3 letter combinations aren't honored
df['patrn'] = df.apply( lambda x: '|'.join(x['Characters Split']), axis=1)
def find_matches(x):
# print(x.name) # index number
new_df = df[~df.index.isin([x.name])] # all rows except current index
return set(new_df.loc[df['patrn'].str.contains(x['patrn'], case=False)]['Unnamed: 0'].tolist())
df['Names with common 3-letters'] = df.apply(lambda x: find_matches(x), axis=1)
df
Output
Unnamed: 0 Characters Length Characters Split A B C D Names with common 3-letters patrn
0 FROKDUWJU 9 [FRO, KDU, WJU] FRO KDU WJU NaN {FROIEUSKIKIR, ORIUWJZSRFRO} FRO|KDU|WJU
1 IDJWPZSUR 9 [IDJ, WPZ, SUR] IDJ WPZ SUR NaN {} IDJ|WPZ|SUR
2 UCFURKIRODCQ 12 [UCF, URK, IRO, DCQ] UCF URK IRO DCQ {URKIFJVUR, QAZWREDCQIBR} UCF|URK|IRO|DCQ
3 ORI 3 [ORI] ORI NaN NaN NaN {ORIUWJZSRFRO} ORI
4 PROIRKIQARTIBPO 15 [PRO, IRK, IQA, RTI, BPO] PRO IRK IQA RTI {} PRO|IRK|IQA|RTI|BPO
5 QAZWREDCQIBR 12 [QAZ, WRE, DCQ, IBR] QAZ WRE DCQ IBR {UCFURKIRODCQ} QAZ|WRE|DCQ|IBR
6 PLPRUFSWURKI 12 [PLP, RUF, SWU, RKI] PLP RUF SWU RKI {RUFOFR} PLP|RUF|SWU|RKI
7 FROIEUSKIKIR 12 [FRO, IEU, SKI, KIR] FRO IEU SKI KIR {PIMIEU, FROKDUWJU, ORIUWJZSRFRO, IEU} FRO|IEU|SKI|KIR
8 ORIUWJZSRFRO 12 [ORI, UWJ, ZSR, FRO] ORI UWJ ZSR FRO {FROKDUWJU, FROIEUSKIKIR, ORI} ORI|UWJ|ZSR|FRO
9 URKIFJVUR 9 [URK, IFJ, VUR] URK IFJ VUR NaN {UCFURKIRODCQ} URK|IFJ|VUR
10 RUFOFR 6 [RUF, OFR] RUF OFR NaN NaN {PLPRUFSWURKI} RUF|OFR
11 IEU 3 [IEU] IEU NaN NaN NaN {PIMIEU, FROIEUSKIKIR} IEU
12 PIMIEU 6 [PIM, IEU] PIM IEU NaN NaN {FROIEUSKIKIR, IEU} PIM|IEU