Say I have a json file such as
[{'start': '11.240', 'end': '11.840', 'word': 'sure', 'v': 1},
{'start': '12.740', 'end': '13.130', 'word': 'look', 'v': 1},
{'start': '14.140', 'end': '14.480', 'word': 'no no', 'v': 1},
{'start': '14.480', 'end': '14.620', 'word': "we're", 'p': ',', 'v': 1},
{'start': '14.620', 'end': '14.790', 'word': 'not', 'v': 1},
{'start': '14.790', 'end': '15.050', 'word': 'going', 'v': 1}]
I could just loop through it like
i = 0
for obj in objects:
i = i len(obj["word"].split())
but for a large directory with a large number of files, this seems to be bit slow. How can I count this in a efficient manner?
CodePudding user response:
You can use the sum() function instead of writing your own loop. And instead of splitting the string, which has to allocate a new list, just count the number of spaces (assuming each word is separated by just one space).
word_count = sum(obj["word"].count(" ") 1 for obj in objects)
CodePudding user response:
use sum():
count = sum(len(obj["word"].split()) for obj in objects)
The second method is mine:
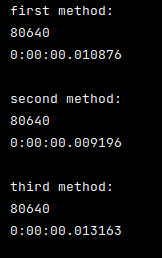
Output:
CodePudding user response:
sum()
count = sum(len(obj["word"].split()))
for obj in objects