I am trying to merge employee history records and get minimum of start date and maximum of end date when there is no other change in any other dimension columns (Employee, Department, Job, Position Status).
Input:
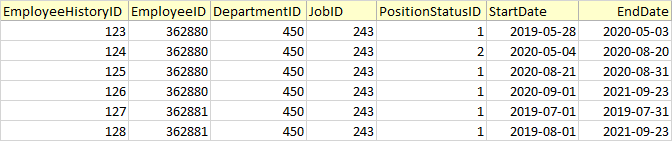
Output:

Script for table creation & populating data:
create table EmployeeHistory (EmployeeHistoryID INT,
EmployeeID INT,
DepartmentID INT,
JobID INT,
PositionStatusID INT,
StartDate DATE,
EndDate DATE)
insert into EmployeeHistory values (123, 362880, 450, 243, 1, '2019-05-28', '2020-05-03')
insert into EmployeeHistory values (124, 362880, 450, 243, 2, '2020-05-04', '2020-08-20')
insert into EmployeeHistory values (125, 362880, 450, 243, 1, '2020-08-21', '2020-08-31')
insert into EmployeeHistory values (126, 362880, 450, 243, 1, '2020-09-01', '2021-09-23')
insert into EmployeeHistory values (127, 362881, 450, 243, 1, '2019-07-01', '2019-07-31')
insert into EmployeeHistory values (128, 362881, 450, 243, 1, '2019-08-01', '2021-09-23')
When I use analytical functions or group by it is merging row 1, 3 & 4, but I want to merge only 3 & 4 as all other columns are same. Even though Row 1 is same as 3 & 4, in order to maintain the history row 1 is not supposed to be merged to 3 &4 in this scenario.
Sample code, I am using:
select distinct *
from (select MAX(EmployeeHistoryID) OVER (PARTITION BY EmployeeID, DepartmentID, JobID, PositionStatusID) AS EmployeeHistoryID,
EmployeeID,
DepartmentID,
JobID,
PositionStatusID,
MIN(StartDate) OVER (PARTITION BY EmployeeID, DepartmentID, JobID, PositionStatusID) AS StartDate,
MAX(EndDate) OVER (PARTITION BY EmployeeID, DepartmentID, JobID, PositionStatusID) AS EndDate
from EmployeeHistory) m
CodePudding user response:
This is a type of gaps-and-islands problem (a genre of problems relating to combining adjacent rows with similar information).
In your data, your records for each employee perfectly "tile" together. There are no gaps. The start date for one row is the end date plus one day of the previous row for the employee.
This allows you to solve the problem only using window functions. Avoiding aggregation is usually a performance benefit. The idea is to find the first row where there is a change, keep that row and calculate the end date. There is a slight complication for the final end date:
select eh.EmployeeHistoryID, eh.EmployeeID, eh.DepartmentID, eh.JobID, eh.PositionStatusID, eh.StartDate,
lead(dateadd(day, -1, StartDate), 1, max_EndDate) over (partition by EmployeeId order by StartDate) as EndDate
from (select eh.*,
lag(StartDate) over (partition by EmployeeID order by StartDate) as prev_StartDate,
lag(StartDate) over (partition by EmployeeID, DepartmentID, JobID, PositionStatusID order by StartDate) as prev_StartDate_same,
max(EndDate) over (partition by EmployeeId) as max_EndDate
from EmployeeHistory eh
) eh
where prev_StartDate_same is null or prev_StartDate_same <> prev_StartDate
order by EmployeeHistoryID;
Here is a db<>fiddle.
CodePudding user response:
If I understood correctly, this is easily achievable using group by. See if this meets the expectation:
SELECT Max(employeehistoryid) AS EmployeeHistoryID,
employeeid,
departmentid,
jobid,
positionstatusid,
Min(startdate) AS StartDate,
Max(enddate) AS EndDate
FROM employeehistory
GROUP BY employeeid,
departmentid,
jobid,
positionstatusid