I have a pandas dataframe df which looks as shown. (df.to_dict() is given at the end):
model scenario module
AIM/CGE 2.0 ADVANCE_2020_1.5C-2100 wind_total_share high high
SSP1-19 wind_total_share high high
SSP2-19 wind_total_share high high
AIM/CGE 2.1 CD-LINKS_NPi2020_400 wind_total_share high high
TERL_15D_LowCarbonTransportPolicy wind_total_share medium medium
TERL_15D_NoTransportPolicy wind_total_share medium medium
GCAM 4.2 SSP1-19 wind_total_share medium medium
IMAGE 3.0.1 IMA15-AGInt wind_total_share low low
IMA15-Def wind_total_share low low
IMA15-Eff wind_total_share low low
model, scenario, and module are indices while Infrastructure and Investment are two columns of the dataframe. I'd like to convert these two columns into the matrix format, where Infrastructure is similar to x-axis and Investment in similar to Y-axis. Furthermore, both in Infrastructure and Investment, I need to classify them into Low, Medium and High.
In the cells, I'd like to have the name of model and scenarios that satisfy the given category (low/medium/high) for given variable (Infrastructure of Investment) as shown in the screenshot below. There could also be cases when a scenario is high for Infrastructure, but low or medium for Investment and vice versa.
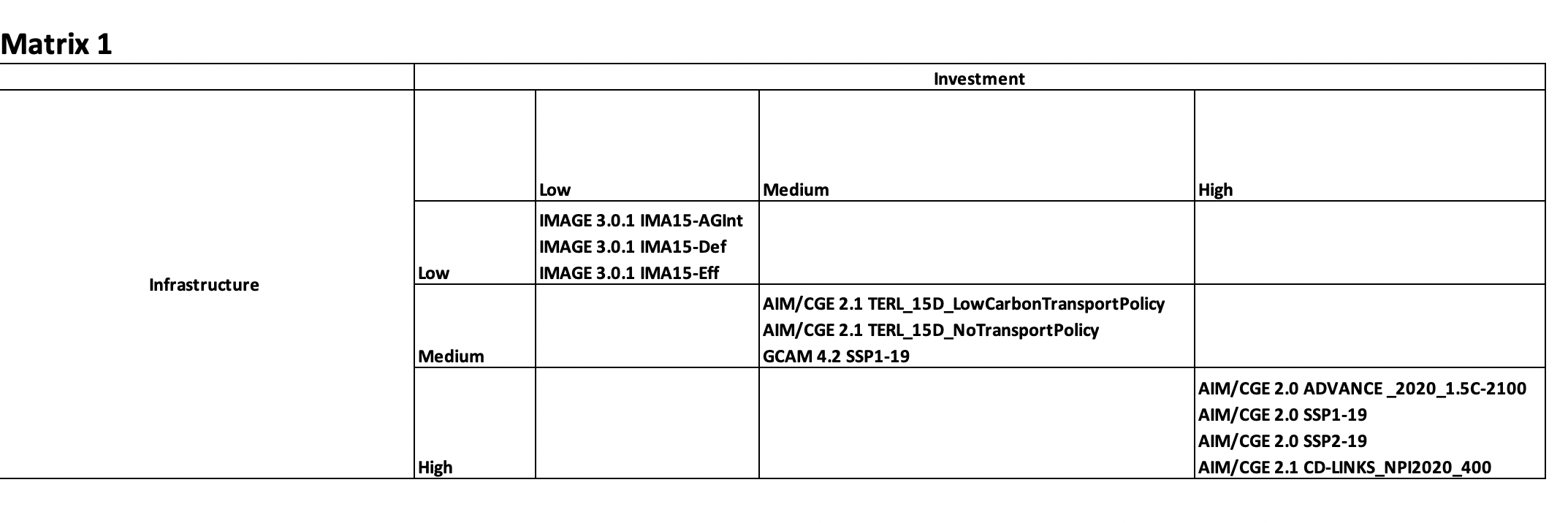
I also want to have another matrix, which shows the number of scenarios that fall into given cell. The second matrix matrices should look something as shown:

I am not familiar with getting such matrix format by modifying the existing pandas dataframe. Are there any functions, or module available that could be used for this purpose? How can I convert my dataframe to the matrix format as shown in the screenshots using Python?
df.to_dict() looks as follows:
{'Infrastructure': {('AIM/CGE 2.0',
'ADVANCE_2020_1.5C-2100',
'wind_total_share'): 'high',
('AIM/CGE 2.0', 'SSP1-19', 'wind_total_share'): 'high',
('AIM/CGE 2.0', 'SSP2-19', 'wind_total_share'): 'high',
('AIM/CGE 2.1', 'CD-LINKS_NPi2020_400', 'wind_total_share'): 'high',
('AIM/CGE 2.1',
'TERL_15D_LowCarbonTransportPolicy',
'wind_total_share'): 'medium',
('AIM/CGE 2.1', 'TERL_15D_NoTransportPolicy', 'wind_total_share'): 'medium',
('GCAM 4.2', 'SSP1-19', 'wind_total_share'): 'medium',
('IMAGE 3.0.1', 'IMA15-AGInt', 'wind_total_share'): 'low',
('IMAGE 3.0.1', 'IMA15-Def', 'wind_total_share'): 'low',
('IMAGE 3.0.1', 'IMA15-Eff', 'wind_total_share'): 'low'},
'Investment': {('AIM/CGE 2.0',
'ADVANCE_2020_1.5C-2100',
'wind_total_share'): 'high',
('AIM/CGE 2.0', 'SSP1-19', 'wind_total_share'): 'high',
('AIM/CGE 2.0', 'SSP2-19', 'wind_total_share'): 'high',
('AIM/CGE 2.1', 'CD-LINKS_NPi2020_400', 'wind_total_share'): 'high',
('AIM/CGE 2.1',
'TERL_15D_LowCarbonTransportPolicy',
'wind_total_share'): 'medium',
('AIM/CGE 2.1', 'TERL_15D_NoTransportPolicy', 'wind_total_share'): 'medium',
('GCAM 4.2', 'SSP1-19', 'wind_total_share'): 'medium',
('IMAGE 3.0.1', 'IMA15-AGInt', 'wind_total_share'): 'low',
('IMAGE 3.0.1', 'IMA15-Def', 'wind_total_share'): 'low',
('IMAGE 3.0.1', 'IMA15-Eff', 'wind_total_share'): 'low'}}
CodePudding user response:
pivot_table could help here.
The 2nd matrix can be directly obtained with:
df.assign(values=1).pivot_table(values='values', index='Infrastructure',
columns='Investment', aggfunc=sum)
which gives:
Investment high low medium
Infrastructure
high 4.0 NaN NaN
low NaN 3.0 NaN
medium NaN NaN 3.0
For the first one, you could first reset the index to build the expected values:
temp = df.reset_index(2, drop=True).reset_index()
temp['value'] = temp['level_0'] ' ' temp['level_1']
df2 = temp.pivot_table(values = 'value', index='Infrastructure',
columns='Investment', aggfunc=list)
In df2 multiple identifiers are grouped in a list. If you want them one per row, you can explode the dataframe:
df2.explode('high').explode('medium').explode('low')
to get
Investment high low medium
Infrastructure
high AIM/CGE 2.0 ADVANCE_2020_1.5C-2100 NaN NaN
high AIM/CGE 2.0 SSP1-19 NaN NaN
high AIM/CGE 2.0 SSP2-19 NaN NaN
high AIM/CGE 2.1 CD-LINKS_NPi2020_400 NaN NaN
low NaN IMAGE 3.0.1 IMA15-AGInt NaN
low NaN IMAGE 3.0.1 IMA15-Def NaN
low NaN IMAGE 3.0.1 IMA15-Eff NaN
medium NaN NaN AIM/CGE 2.1 TERL_15D_LowCarbonTransportPolicy
medium NaN NaN AIM/CGE 2.1 TERL_15D_NoTransportPolicy
medium NaN NaN GCAM 4.2 SSP1-19
CodePudding user response:
I did some brainstorming for a while and came up with the solution myself. It is long, but it looks like this.
First, I made the list of scenarios which are high, medium and low for both Infrastructure and Investment respectively:
infra_high = (df[df["Infrastructure"]=="high"].index.get_level_values(0) " " df[df["Infrastructure"]=="high"].index.get_level_values(1)).to_list()
infra_medium = (df[df["Infrastructure"]=="medium"].index.get_level_values(0) " " df[df["Infrastructure"]=="medium"].index.get_level_values(1)).to_list()
infra_low = (df[df["Infrastructure"]=="low"].index.get_level_values(0) " " df[df["Infrastructure"]=="low"].index.get_level_values(1)).to_list()
invest_high = (df[df["Investment"]=="high"].index.get_level_values(0) " " df[df["Investment"]=="high"].index.get_level_values(1)).to_list()
invest_medium = (df[df["Investment"]=="medium"].index.get_level_values(0) " " df[df["Investment"]=="medium"].index.get_level_values(1)).to_list()
invest_low = (df[df["Investment"]=="low"].index.get_level_values(0) " " df[df["Investment"]=="low"].index.get_level_values(1)).to_list()
Next, I did the intersection of the scenarios which are high, high; high, medium and high, low for Infrastructure and Investment as follows:
i1 = list(set(infra_high).intersection(set(invest_high)))
i2 = list(set(infra_high).intersection(set(invest_medium)))
i3 = list(set(infra_high).intersection(set(invest_low)))
i4 = list(set(infra_medium).intersection(set(invest_high)))
i5 = list(set(infra_medium).intersection(set(invest_medium)))
i6 = list(set(infra_medium).intersection(set(invest_low)))
i7 = list(set(infra_low).intersection(set(invest_high)))
i8 = list(set(infra_low).intersection(set(invest_medium)))
i9 = list(set(infra_low).intersection(set(invest_low)))
Next, using the Excel file, I recreated the matrix I wanted to make:
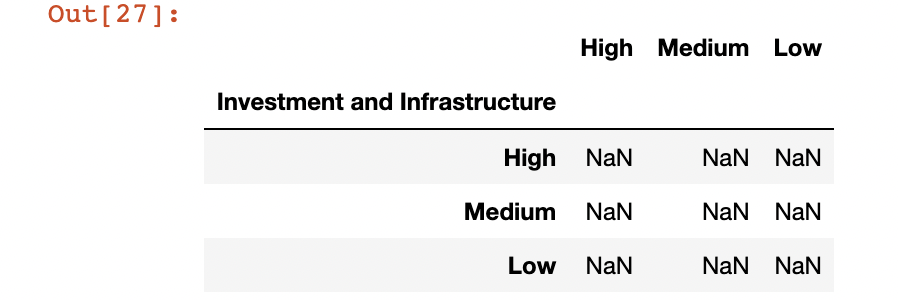
Then, I assigned the list for each cell of the dataframe as follows:
landing_zone1.loc["High","High"] = i1
landing_zone1.loc["High","Medium"] = i2
landing_zone1.loc["High","Low"] = i3
landing_zone1.loc["Medium","High"] = i4
landing_zone1.loc["Medium","Medium"] = i5
landing_zone1.loc["Medium","Low"] = i6
landing_zone1.loc["Low","High"] = i7
landing_zone1.loc["Low","Medium"] = i8
landing_zone1.loc["Low","Low"] = i9
And I did the same for matrix of number of scenarios using len() of each list.