Thank you, I only 3 weeks into learning Pandas, and I am getting unexpected results, any guidance would be appreciated.
I would like to merge two DataFrames together and retain my set_index.
I have a simple DataFrame
import pandas as pd
data = {
'part_number': [123,123,123],
'part_name': ['some name in 11', 'some name in 12', 'some name in 13'],
'part_size': [11,12,13]
}
df = pd.DataFrame(data=data)
df.set_index('part_name', inplace=True)

I groupby the part_sizes, and merge.
This is where my knowledge breaks down, I lose my index which is the part_name.
I see there are joins and concats, am I using the wrong syntax?
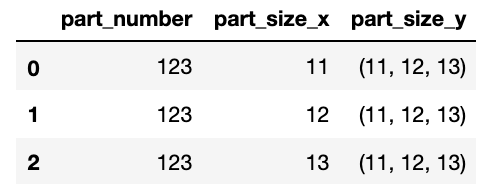
part_size_merge = df.groupby(['part_number'], dropna=False)['part_size'].agg(tuple).to_frame()
merged = df.merge(part_size_merge, on=['part_number'])
display(merged.head())
I tried concat, however, it looks like it stacks the two df's together, which isn't how I'd like it.
x = pd.concat([df, part_size_merge], axis=0, join='inner')
x.head()
CodePudding user response:
Yes that is normal merge
out = df.reset_index().merge(part_size_merge, on=['part_number']).set_index('part_name')
Out[334]:
part_number part_size_x part_size_y
part_name
some name in 11 123 11 (11, 12, 13)
some name in 12 123 12 (11, 12, 13)
some name in 13 123 13 (11, 12, 13)