i begun to learn python for data science, but after sql i started to fail slicing with python.
So my data is:
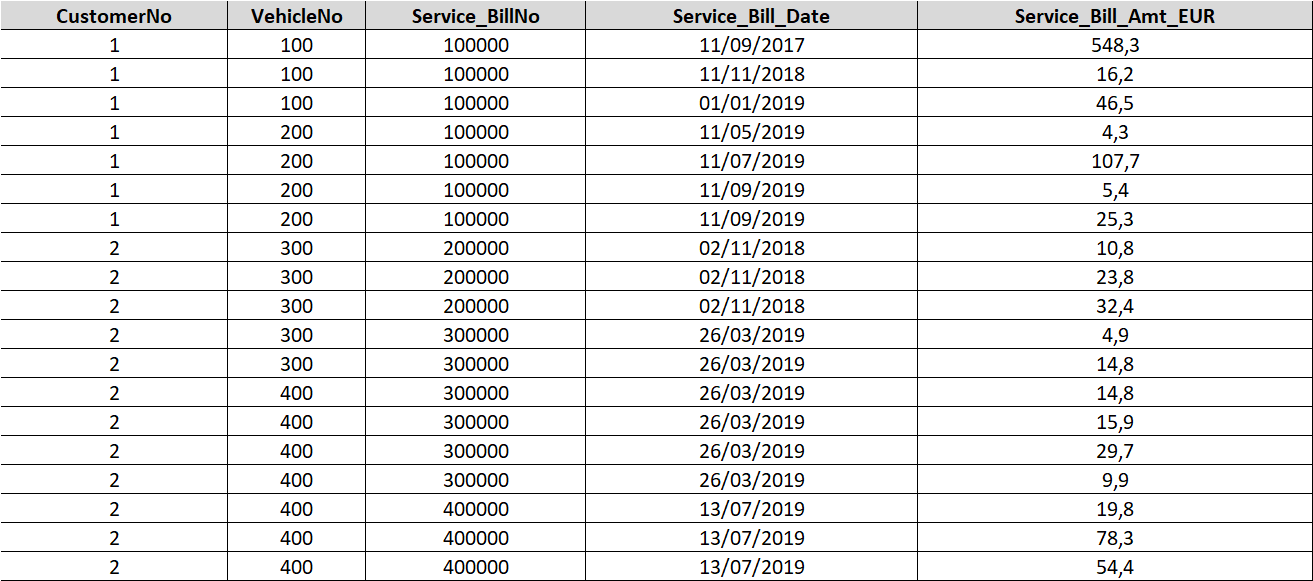
and i needed it to look like this;

How can i do this with python without using SQL libraries.
CodePudding user response:
Well this is a very broad question but I would suggest to look into using pandas framework. Look it up find some tutorials. It will make everything easy(as easy as data science can be anyway).
CodePudding user response:
using a pandas dataframe you could them merge them Typically the Avg_Bill_Amount would be the result of a groupby like so:
df.groupby(['Customer_number']).mean()
For the last date I would try:
df.groupby(['Customer_number'], sort=False)['service_bill_amount'].max()
then you would have to merge them together on the customer number
CodePudding user response:
You can use "pandas" library. Convert it into a dataframe and use groupby() function.
Let's say you have a dataframe data containing first table from your question.
First of all, you have to drop unnecessary columns.
data.drop(['Service_Bill_Date'], inplace=True)
Now with groupby
data.groupby(by=['CustomerNo']).mean()