Question - How to best attempt the problem as nested loops is slowing the process and not giving the desired result
Same thing can be done in the Excel using Hlookup, but as it is a repetitive exercise, I need to automate it
I have the below lookup table.
lookup = pd.DataFrame({'Fruit': ['Apple','Mango','Guava'],'Rate':[20,30,25],
'Desc':['Apple rate is higher', 'Mango rate is higher', 'Guava rate is higher']})
My objective is to mark desc in my input data wherever the rate is greater than as mentioned in lookpup table
input_data = pd.DataFrame({'Id':[1,2,3,4,5], 'Apple':[24,27,30,15,18], 'Mango':[28,32,35,12,26],
'Guava':[20,23,34,56,23]})
Expected Output data sample -
output_data = pd.DataFrame({'Id':[1,2,3,4,5], 'Apple':[24,27,30,15,18], 'Mango':[28,32,35,12,26],
'Guava':[20,23,34,56,23], 'Desc':['Apple rate is higher',
'Apple rate is higher, Mango rate is higher',
'Apple rate is higher, Mango rate is higher, Guava rate is higher',
'Guava rate is higher', '']})
I have tried using the loop and created two list which gives me the index and value to be inserted. I am confused how to progress to next step and it seems a very slow method as I have multiple nested loops
for i in range(0,len(lookup)):
var1 = lookup['Fruit'][i]
value1 = lookup['Rate'][i]
desc1 = lookup['Desc'][i]
for j in range(0, len(input_data.columns)):
var2 = input_data.columns[j]
a=[]
b=[]
if var1 == var2:
for k in range(0, len(input_data)):
if input_data[var2][k] > value1:
a.append(desc1)
b.append(k)
print (a)
print (b)
Output of my code
['Apple rate is higher', 'Apple rate is higher', 'Apple rate is higher'] [0, 1, 2]
['Mango rate is higher', 'Mango rate is higher'] [1, 2]
['Guava rate is higher', 'Guava rate is higher'] [2, 3]
CodePudding user response:
How you do what you asked for
import numpy as np
import pandas as pd
input_data['desc'] = np.sum([(rate < input_data[col]).apply(lambda x: desc ", " if x else '')
for rate,desc,col in zip(lookup.Rate, lookup.Desc, input_data.columns[1:])], axis=0)
input_data['desc'] = input_data['desc'].str.rstrip(", ")
Since this is pretty dense code I will try to explain a bit. For each column
rate < input_data[col]
gives you a true/false list being true whenever the fruit value is over the rate. Then .apply(lambda x: desc ", " if x else '') replaces trues with the relevant text and false with an empty string. The np.sum sums the columns i.e. puts together the strings and finally the .str.rstrip(", ") removes ", " in the end.
and you get
Id Apple Mango Guava desc
0 1 24 28 20 Apple rate is higher
1 2 27 32 23 Apple rate is higher, Mango rate is higher
2 3 30 35 34 Apple rate is higher, Mango rate is higher, Gu...
3 4 15 12 56 Guava rate is higher
4 5 18 26 23
What you should have asked instead
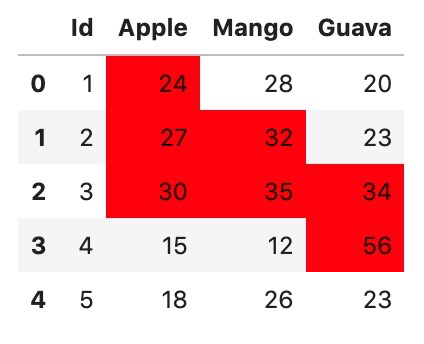
I am a visual person and prefer the relevant columns to be colored instead of having some extra text.
You could do that like this
input_data.style.highlight_between(left=[np.nan,*lookup.Rate], axis=1, color="red")
CodePudding user response:
This can be solved using a combination of pd.merge, melt, and groupby.
tmp = pd.merge(
input_data.melt(ignore_index=False) \
.reset_index(),
lookup,
how="inner",
left_on="variable",
right_on="Fruit"
)
vals = tmp.loc[tmp["value"] > tmp["Rate"]] \
.groupby("index") \
.agg({"Desc": ", ".join})
pd.merge(input_data, vals, right_index=True, left_index=True, how="left")
Id Apple Mango Guava Desc
0 1 24 28 20 Apple rate is higher
1 2 27 32 23 Apple rate is higher, Mango rate is higher
2 3 30 35 34 Apple rate is higher, Mango rate is higher, Gu...
3 4 15 12 56 Guava rate is higher
4 5 18 26 23 NaN
tmp is a join between the lookup and input_data in order to have them in one DataFrame so we can compare the values quickly between columns and keep the Desc attached to the relevant rows. vals ends up being the rows where the condition you describe is met and then we groupby the index that we kept from the original input_data table and concatenate the values for the Desc column. Lastly the output joins the input_data on the vals using the original index from the input_data as the join condition. We make sure to use a left join to keep the original rows if the condition is not met.