I need help interpreting this (it's part of an assignment which I'm stuck with):
"Create a plot for each subject where you plot the estimated function (on the target.contrast range from 0-1) based on the fitted values of a model (use glm) that models correct as dependent on target.contrast."
The variables:
subject: values 1:36 naming each subject
target contrast: Continuous variable having values in the range 0-1
correct: Binary variable: either 0 or 1
Length of data set is 5,000 rows.
Now to my question: What do you think is meant by 'estimated function'? Random intercepts? Estimated values? I'm quite confused.
So far, I've made this:
# modelling correct as dependent on target.contrast
model1 <- glmer(correct ~ target.contrast (1 | subject), data = exp2_staircase, family = binomial)
plot(exp2_staircase$target.contrast, model1$fitted.values, xlab='Target contrast',
ylab='Probability of being correct/incorrect',
main='Logistic regression - fitted values')
CodePudding user response:
Since the requirement is to use a glm for each group (here: manufacturer), we can do exactly this:
library(tidyverse)
estimates <-
mpg %>%
nest(-manufacturer) %>%
mutate(
model = data %>% map(~ glm(displ ~ hwy, data = .x)),
estimates = model %>% map2(data, ~ .x %>% predict(newdata = .y))
) %>%
select(manufacturer, data, estimates) %>%
unnest(estimates) %>%
unnest(data) %>%
mutate(displ = estimates) %>%
distinct(manufacturer, hwy, .keep_all = TRUE)
#> Warning: All elements of `...` must be named.
#> Did you want `data = c(model, displ, year, cyl, trans, drv, cty, hwy, fl, class)`?
bind_rows(
mpg %>% mutate(type = "truth"),
estimates %>% mutate(type = "predicted")
) %>%
filter(manufacturer %in% c("audi", "volkswagen")) %>%
ggplot(aes(hwy, displ, color = type, shape = manufacturer))
geom_point()
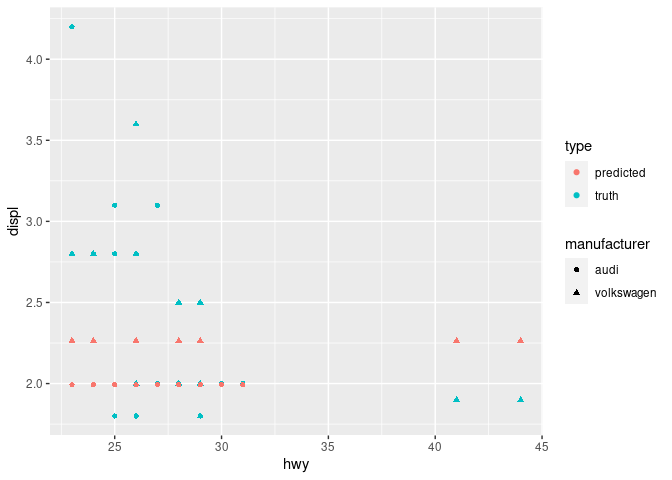
Created on 2021-10-03 by the reprex package (v2.0.1)
Random factors are only used, if the prediction is based on new groups the model has not seen yet.