so I have two sets of data that I am merging and duplicating. I am using the disctinct_at() function from dlpyr to deduplicate after merging the 2 datasets in R with rbind().
I discovered something interesting but I'm not sure if it's by chance. I have two datasets A & B. There are duplicates in A & B but B has priority as far as the category I am looking for. So if an observation is in both A & B, I would like to see the category from dataset B.
Here is my code.
library(dplyr)
a <- data.frame("ID" = c(123,124,125,126),
"Category" = c("Blue", "Blue", "Red", "Red"),
"Helper" = c("dataset_a","dataset_a","dataset_a","dataset_a" ))
b <- data.frame("ID" = c(127,124,125,128),
"Category" = c("Green", "Green", "Orange", "Orange"),
"Helper" = c("dataset_b","dataset_b","dataset_b","dataset_b"))
bind_1 <- rbind(a,b)
bind_2 <- rbind(b,a)
bind_final_1<- bind_1 %>%
#Unqiue
distinct_at(vars(ID), .keep_all = TRUE)
bind_final_2<- bind_2 %>%
#Unqiue
distinct_at(vars(ID), .keep_all = TRUE)
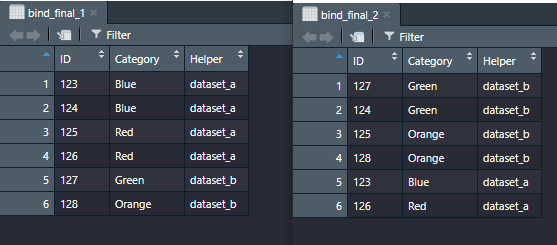
The deduplication has different outputs by changing the bind order. bind_final_1 keeps the category from dataset A. While bind_final 2 keeps the category from dataset B? bind_final_2 has the desired output I am looking for but is this output by chance or is there another piece of code I can add to my distinct_at() to always get this output?
CodePudding user response:
Here's one way to address this:
First we group by ID and use n() to count when we have multiple rows for an ID. Then we filter to where Helper == dataset_b or n == 1. n == 1 is a unique ID, so we keep it. If n > 1 then we keep the row for dataset_b
library(tidyverse)
bind_1 %>%
group_by(ID) %>%
mutate(n = n()) %>%
filter(Helper == "dataset_b" | n == 1) %>%
arrange(ID)
ID Category Helper n
<dbl> <fct> <fct> <int>
1 123 Blue dataset_a 1
2 124 Green dataset_b 2
3 125 Orange dataset_b 2
4 126 Red dataset_a 1
5 127 Green dataset_b 1
6 128 Orange dataset_b 1
CodePudding user response:
You have the correct output in bind_final_2 and it is not by chance. It would always return the correct output. distinct would always keep the 1st occurrence of unique key (ID here) since you are doing bind_2 <- rbind(b,a) the rows in b would always be ahead than rows in a.
Also you can use the following -
library(dplyr)
bind_rows(b, a) %>% distinct(ID, .keep_all = TRUE)