This problem is a bit hard for me to wrap my head around so I hope I can explain it properly below. I have a data frame with a lot of rows but only 3 columns like below:
data = {'line_group': [1,1,8,8,4,4,5,5],
'route_order': [1,2,1,2,1,2,1,2],
'StartEnd':['20888->20850','20888->20850','20888->20850','20888->20850',
'20961->20960','20961->20960','20961->20960','20961->20960']}
df = pd.DataFrame(data)
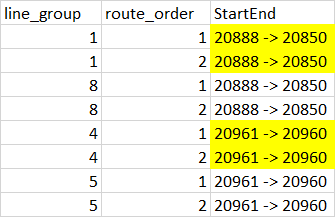
In the end, I want to use this data to plot routes between points for instance 20888 to 20850. But the problem is that there are a lot of trips/line_group that also goes through these two points so when I do plot things, it will be overlapping and very slow which is not what I want.
So I only want the first line_group which has the unique StartEnd like in the data frame below:
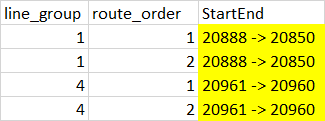
I believe it could have something to do with groupby like in the following code below that I have tried but it doesn't produce the results I want. And in the full dataset route orders aren't usually just from 1 point to another and can be up to much more (E.g 1,2,3,4,...).
drop_duplicates(subset='StartEnd', keep="first")
CodePudding user response:
Group by StartEnd and keep only the first line_group value
Then filter to rows which contain the unique line groups
unique_groups = df.groupby('StartEnd')['line_group'].agg(lambda x: list(x)[0]).reset_index()
StartEnd line_group
20888->20850 1
20961->20960 4
unique_line_groups = unique_groups['line_group']
filtered_df = df[df['line_group'].isin(unique_line_groups)]
Final Output
line_group route_order StartEnd
1 1 20888->20850
1 2 20888->20850
4 1 20961->20960
4 2 20961->20960
CodePudding user response:
You can add in route_order to the argument subset to get output you want.
In [8]: df.drop_duplicates(subset=['StartEnd', 'route_order'], keep='first')
Out[8]:
line_group route_order StartEnd
0 1 1 20888->20850
1 1 2 20888->20850
4 4 1 20961->20960
5 4 2 20961->20960
CodePudding user response:
You can use groupby.first():
df.groupby(["route_order", "StartEnd"], as_index=False).first()
output:
route_order StartEnd line_group
0 1 20888->20850 1
1 1 20961->20960 4
2 2 20888->20850 1
3 2 20961->20960 4