When using a copy activity in Azure Data Factory to copy a typical CSV file with a header row into Parquet sink, the SINK fails with the following error due to the column names in the CSV having spaces in the header.
The column name is invalid. Column name cannot contain these character:[,;{}()\n\t=]
The CSV is pipe delimited and displays just fine using the preview feature of the dataset with the first row marked as the header. I see no options to handle this use-case on the parquet side (sink) of the copy activity. I realize this can probably be addressed using a data flow to transform column names to remove spaces, but does that mean the native copy activity is incapable of handling this condition where a space in included in a header row?

EDIT: I should have added that dataset uses default mappings so that we can use the same dataset for any CSV to PARQUET copy. The answer provided will work for explicit mappings, but we don't see any resolution for folks who use default/dynamic mappings since we do not have access to the column names to remove spaces.
CodePudding user response:
As we can note from the official Doc 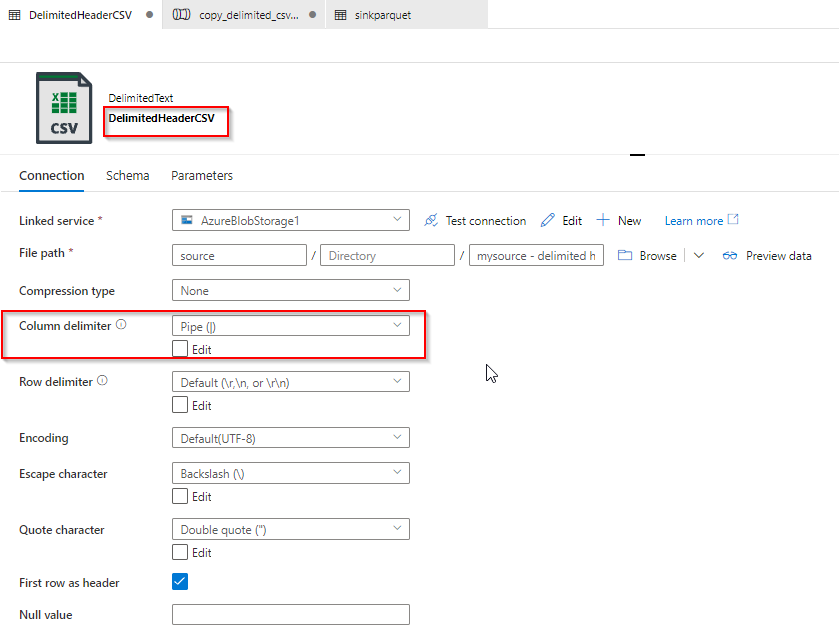
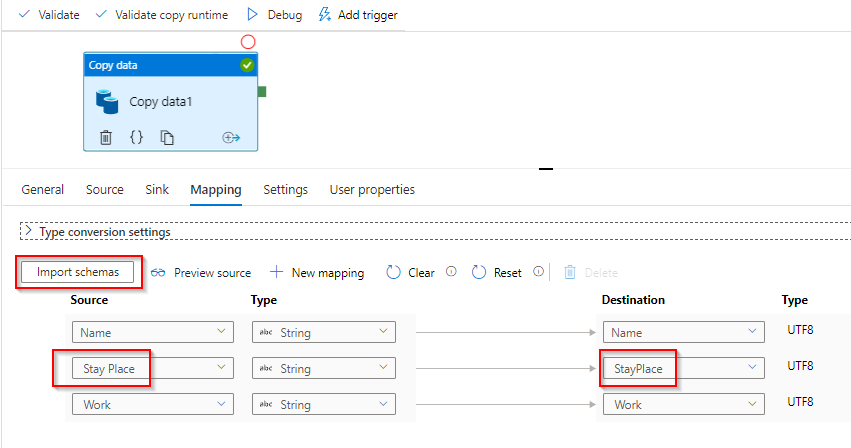
2. If feasible, in mapping settings > import schema and rename the column name without spaces in destination column.
This is still an ongoing issue or request, follow here for more.