I'm new in this, appreciate your patience. I have this txt file, 'student.txt', that I want to write into a csv file, 'student.csv'.
student.txt
name-> Alice
name-> Sam
sibling-> Kate,
sibling-> Luke,
hobby_1-> football
hobby_2-> games
name-> Alex
name-> Ramsay
hobby_1-> dance
hobby_2-> swimming
hobby_3-> jogging
Expected output in csv:
Name Sibling Hobbies
name-> Alice N/A N/A
name-> Sam sibling-> Kate hobby_1-> football
sibling-> Luke hobby_2-> games
name-> Alex N/A N/A
name-> Ramsay N/A hobby_1-> dance
hobby_2-> swimming
hobby_3-> jogging
Code I've done so far:
file = open('student.txt' , 'r')
with open('student.csv' , 'w') as writer:
writer.write ('Name,Sibling,Hobbies\n')
for eachline in file:
if 'name' in eachline:
writer.write (eachline)
if 'sibling' in eachline:
writer.write (eachline)
if 'hobby' in eachline:
writer.write (eachline)
Basically, any data after a name is captured before the next name. But I'm not sure how to put it orderly in csv, especially when some names don't have siblings / hobbies, to put it as N/A.
CodePudding user response:
You can approach the problem as follows:
- parse the text into a dictionary
- generate a list for each desired column in the csv
- write the lists as columns in a csv file
Sample implementation:
file = open('student.txt' , 'r')
### parse the text into a dictionary
# remove whitespaces and commas from each line
lines = [x.strip().replace(',', '') for x in file]
# initialize dictionary
data = dict()
index = 0
while index < len(lines):
line = lines[index]
# for each name, generate a dictionary containing two lists
if 'name' in line:
# one list for siblings, one list for hobbies
data[line] = {'siblings': [], 'hobbies': []}
name_index = index 1
# populate the lists with the values listed under the name
while (name_index < len(lines)) and ('name' not in lines[name_index]):
if 'sibling' in lines[name_index]:
data[line]['siblings'].append(lines[name_index])
elif 'hobby' in lines[name_index]:
data[line]['hobbies'].append(lines[name_index])
name_index = 1
index = 1
index = 1
# data looks like:
'''
{'name-> Alice': {'siblings': [], 'hobbies': []},
'name-> Sam': {'siblings': ['sibling-> Kate', 'sibling-> Luke'],
'hobbies': ['hobby_1-> football', 'hobby_2-> games']},
'name-> Ramsay': {'siblings': [],
'hobbies': ['hobby_1-> dance', 'hobby_2-> swimming', 'hobby_3-> jogging']}}
'''
### generate a list for each column in the csv
names = []
siblings = []
hobbies = []
null_str = 'N/A'
for key in data:
# add name to names
names.append(key)
# get rows for this name
len_sibs = len(data[key]['siblings'])
len_hobs = len(data[key]['hobbies'])
num_rows = max([len_sibs, len_hobs])
if num_rows == 0:
siblings.append(null_str)
hobbies.append(null_str)
else:
# add (num_rows - 1) empty strings to names
names.extend([''] * (num_rows - 1))
siblings_na_added = False
hobbies_na_added = False
for i in range(num_rows):
# add siblings values with conditions for N/A and ''
if i > (len(data[key]['siblings']) - 1):
if siblings_na_added == False:
siblings.append(null_str)
siblings_na_added = True
else:
siblings.append('')
else:
siblings.append(data[key]['siblings'][i])
# add hobbies values with conditions for N/A and ''
if i > (len(data[key]['hobbies']) - 1):
if hobbies_na_added == False:
hobbies.append(null_str)
hobbies_na_added = True
else:
hobbies.append('')
else:
hobbies.append(data[key]['hobbies'][i])
### write the lists as columns in a csv file
with open('student.csv' , 'w') as writer:
writer.write ('Name,Sibling,Hobbies\n')
for i in range(len(names)):
row = names[i] ',' siblings[i] ',' hobbies[i] '\n'
writer.write(row)
Output read as text:
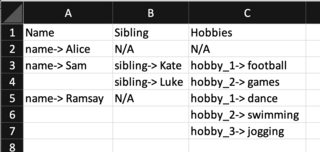
Name,Sibling,Hobbies
name-> Alice,N/A,N/A
name-> Sam,sibling-> Kate,hobby_1-> football
,sibling-> Luke,hobby_2-> games
name-> Ramsay,N/A,hobby_1-> dance
,,hobby_2-> swimming
,,hobby_3-> jogging
Output read as csv in excel:
P.S. the problem was more complicated than I imagined :))