I have a sample of a large dataset as below
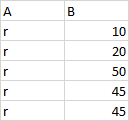
I would like to get the percentage of the count of number of rows with a value above 30 which would give me an output as below
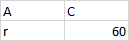
How would I go about achieving this with pandas. I have gotten to this last point of processing my data and a bit stuck with this
CodePudding user response:
You can compare values for greater like 30 with aggregate mean:
df = (df.B > 30).groupby(df['A']).mean().mul(100).reset_index(name='C')
print (df)
A C
0 r 60.0
Or:
df = df.assign(C = df.B > 30).groupby('A')['C'].mean().mul(100).reset_index()