I am currently using this code to draw a histogram.
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.ticker import FormatStrFormatter
data = np.random.randn(82)
fig, ax = plt.subplots()
counts, bins, patches = ax.hist(data, facecolor='yellow', edgecolor='gray')
# Set the ticks to be at the edges of the bins.
ax.set_xticks(bins)
# Set the xaxis's tick labels to be formatted with 1 decimal place...
ax.xaxis.set_major_formatter(FormatStrFormatter('%0.1f'))
# Change the colors of bars at the edges...
twentyfifth, seventyfifth = np.percentile(data, [25, 75])
for patch, rightside, leftside in zip(patches, bins[1:], bins[:-1]):
if rightside < twentyfifth:
patch.set_facecolor('green')
elif leftside > seventyfifth:
patch.set_facecolor('red')
# Label the raw counts and the percentages below the x-axis...
bin_centers = 0.5 * np.diff(bins) bins[:-1]
for count, x in zip(counts, bin_centers):
# Label the raw counts
ax.annotate(str(count), xy=(x, 0), xycoords=('data', 'axes fraction'),
xytext=(0, -18), textcoords='offset points', va='top', ha='center')
# Label the percentages
percent = '%0.0f%%' % (100 * float(count) / counts.sum())
ax.annotate(percent, xy=(x, 0), xycoords=('data', 'axes fraction'),
xytext=(0, -32), textcoords='offset points', va='top', ha='center')
# Give ourselves some more room at the bottom of the plot
plt.subplots_adjust(bottom=0.15)
plt.show()
I want to add x marks (labelled with "orange", "apple", "pineapple") of a given histogram x-axis value on the histogram as shown: 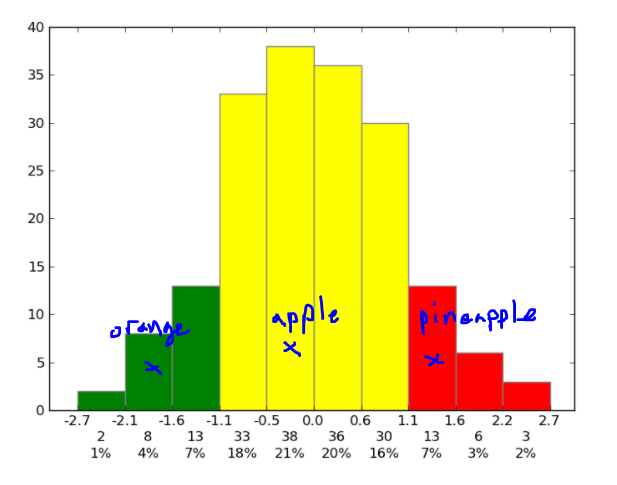
How should I do so?
The x marks do not have a y value.
CodePudding user response:
All stays the same except for these lines:
...
# Change the colors of bars at the edges...
left = []
right = []
twentyfifth, seventyfifth = np.percentile(data, [25, 75])
for patch, rightside, leftside in zip(patches, bins[1:], bins[:-1]):
if rightside < twentyfifth:
patch.set_facecolor('green')
left.append(leftside)
elif leftside > seventyfifth:
patch.set_facecolor('red')
right.append(rightside)
ax.text(left[int(len(left)/2)], 1, 'orange\n x')
ax.text(right[0], 1, 'pineapple\n x')
ax.text((left[int(len(left)/2)] right[0]) / 2, 1, 'apple\n x')
# Label the raw counts and the percentages below the x-axis...
bin_centers = 0.5 * np.diff(bins) bins[:-1]
...
Output:
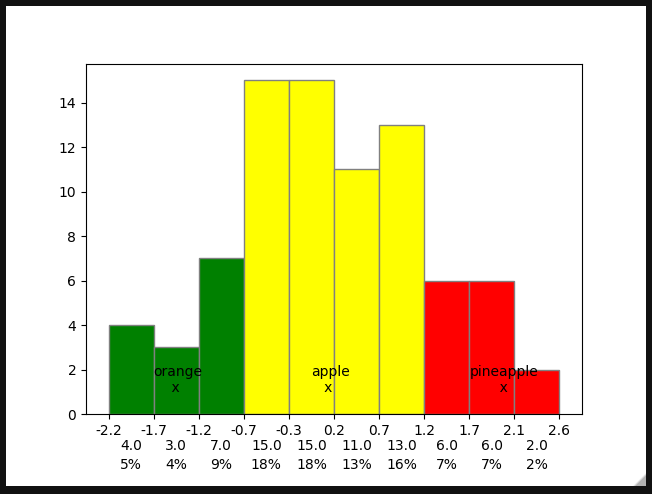
---edit---
OP added the data and asked for an edit.
The code from OP in the question stays as it is, the following lines are to be added after.
data = {'product_name': ['laptop', 'printer', 'tablet', 'desk', 'chair'],'price': [2, 0.1, 2.4, 2.2, 1]}
ax.scatter(data['price'], [1]*len(data['price']), zorder=2, marker='x', c='k')
for i in range(len(data['price'])):
ax.text(data['price'][i]-0.2, 1.5, f"{data['product_name'][i]}")
Output:
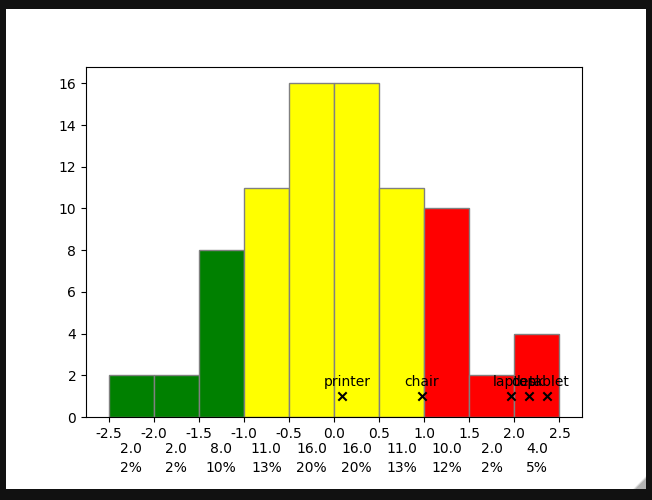
The annotations are overlapping, but this is expected due to the x-values given by the OP (very close to each other).