I have multiple pandas data frames with some common columns and some overlapping rows. I would like to combine them in such a way that I have one final data frame with all of the columns and all of the unique rows (overlapping/duplicate rows dropped). The remaining gaps should be nans.
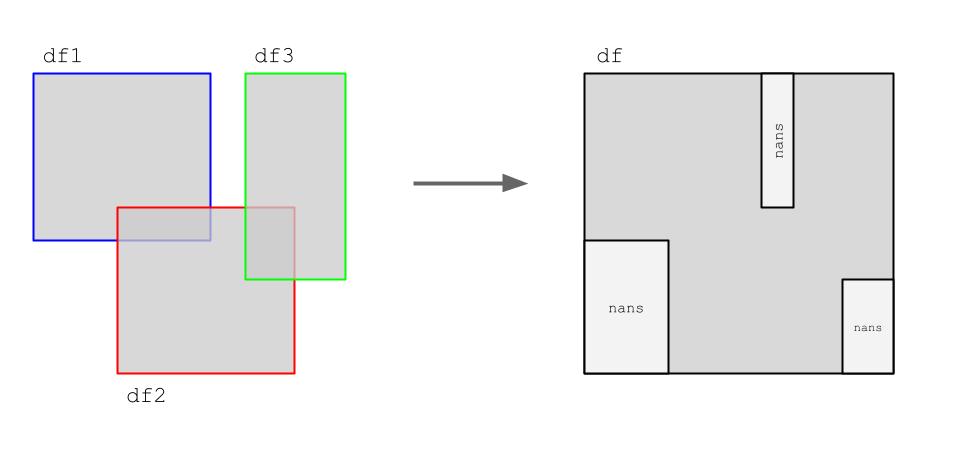
I have come up with the function below. In essence it goes through all columns one by one, appending all of the values from each data frame, dropping the duplicates (overlap), and building a new output data frame column by column.
def combine_dfs(dataframes:list):
## Identifying all unique columns in all data frames
columns = []
for df in dataframes:
columns.extend(df.columns)
columns = np.unique(columns)
## Appending values from each data frame per column
output_df = pd.DataFrame()
for col in columns:
column = pd.Series(dtype="object", name=col)
for df in dataframes:
if col in df.columns:
column = column.append(df[col])
## Removing overlapping data (assuming consistent values)
column = column[~column.index.duplicated()]
## Adding column to output data frame
column = pd.DataFrame(column)
output_df = pd.concat([output_df,column], axis=1)
output_df.sort_index(inplace=True)
return output_df
df_1 = pd.DataFrame([[10,20,30],[11,21,31],[12,22,32],[13,23,33]], columns=["A","B","C"])
df_2 = pd.DataFrame([[33,43,54],[34,44,54],[35,45,55],[36,46,56]], columns=["C","D","E"], index=[3,4,5,6])
df_3 = pd.DataFrame([[50,60],[51,61],[52,62],[53,63],[54,64]], columns=["E","F"])
print(combine_dfs([df_1,df_2,df_3]))
The output, as intended in the visualization, looks like this:
A B C D E F
0 10.0 20.0 30 NaN 50 60.0
1 11.0 21.0 31 NaN 51 61.0
2 12.0 22.0 32 NaN 52 62.0
3 13.0 23.0 33 43.0 54 63.0
4 NaN NaN 34 44.0 54 64.0
5 NaN NaN 35 45.0 55 NaN
6 NaN NaN 36 46.0 56 NaN
This method works well on small data sets. Is there a way to optimize this?
CodePudding user response:
IIUC you can chain combine_first:
print (df_1.combine_first(df_2).combine_first(df_3))
A B C D E F
0 10.0 20.0 30 NaN 50.0 60.0
1 11.0 21.0 31 NaN 51.0 61.0
2 12.0 22.0 32 NaN 52.0 62.0
3 13.0 23.0 33 43.0 54.0 63.0
4 NaN NaN 34 44.0 54.0 64.0
5 NaN NaN 35 45.0 55.0 NaN
6 NaN NaN 36 46.0 56.0 NaN