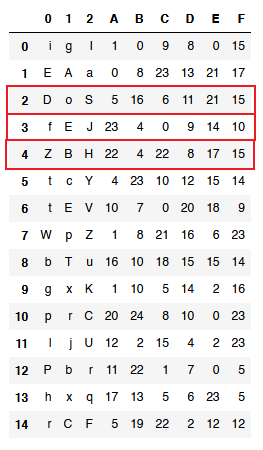
I want to show the rows, which values from columns A-F meets a condition that only single column values is between (0,5> and the rest are greater than 5. Think of it as I want to find out the situation, where only single element is near (e.g. 0-5m distance) from the center of the measurement and the rest of points (columns values) are "further". I have added string columns as a impediment.
I have tried without success below code. Additionaly there is this condition that rest of the columns should have value greater than 5.
df[(df.columns[-6:]>0) & (df.columns[-6:]<=5)]
Minimal reproducible example:
import numpy as np
import pandas as pd
import string
rowsNumber = 15
digitColumnNumber = 6
letterColumnNumber = 3
df_numbers = pd.DataFrame(np.random.randint(0,25,size=(rowsNumber, digitColumnNumber)), columns=list('ABCDEF'))
df_letters = pd.DataFrame(np.arange(rowsNumber*letterColumnNumber).reshape(rowsNumber,letterColumnNumber)).applymap(lambda x: np.random.choice(list(string.ascii_letters)))
df = pd.concat([df_letters, df_numbers], axis=1)
CodePudding user response:
Is this what you are looking for?
df2 = df.loc[:,'A':'F'].copy()
df.loc[df2.clip(0,5).eq(df2).sum(axis=1).eq(1)]
CodePudding user response:
You can simply slice the desired columns, and count the columns whose value if lower or equal to 5 (I made the assumption that the values are greater or equal to zero, but if this is not the case, it it easy to add a second check):
df[df.loc[:,'A':'F'].le(5).sum(1).eq(1)]