Say we have a dataframe like this and want to remove columns when certain conditions met.
df = pd.DataFrame(
np.arange(2, 14).reshape(-1, 4),
index=list('ABC'),
columns=pd.MultiIndex.from_arrays([
['data1', 'data2','data1','data2'],
['F', 'K','R','X'],
['C', 'D','E','E']
], names=['meter', 'Sleeper','sweeper'])
)
df
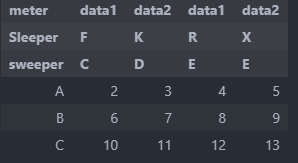
then lets say we want to remove cols only when meter == data1 and sweeper == E
so I tried
df = df.drop(('data1','E'),axis = 1)
KeyError: 'E'
second try
df.drop(('data1','E'), axis = 1, level = 2)
KeyError: "labels [('data1', 'E')] not found in level"
Pandas: drop a level from a multi-level column index?
CodePudding user response:
Seems drop doesn't support selection over split levels ([0,2] here). We can create a mask with the conditions instead using get_level_values:
# keep where not ((level0 is 'data1') and (level2 is 'E'))
col_mask = ~((df.columns.get_level_values(0) == 'data1')
& (df.columns.get_level_values(2) == 'E'))
df = df.loc[:, col_mask]
We can also do this by integer location by excluding the locs that are in a particular index slice, however, this is overall less clear and less flexible:
idx = pd.IndexSlice['data1', :, 'E']
cols = [i for i in range(len(df.columns))
if i not in df.columns.get_locs(idx)]
df = df.iloc[:, cols]
Either approach produces df:
meter data1 data2
Sleeper F K X
sweeper C D E
A 2 3 5
B 6 7 9
C 10 11 13
CodePudding user response:
You have to do them individually, since they are on different levels:
df.drop('data1', axis=1, level='meter').drop('E', axis = 1, level='sweeper')
Out[833]:
meter data2
Sleeper K
sweeper D
A 3
B 7
C 11