I'd like to perform a calculation over an X, Y data to produce a calculated Z. My code is below:
Example Data set for injection_wells.csv
| Name | X | Y | Q |
|---|---|---|---|
| MW-1 | 2517700 | 996400 | 5 |
| MW-2 | 2517770 | 996420 | 5 |
import pandas as pd
import math
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.tri as tri
IW = pd.read_csv (r'Injection_wells.csv')
`Note that - Injection wells is a table of three wells with names, X, Y, and Q (flow rate).`
#pull all the relevant well information by well into their own arrays
MW1 = IW[IW['Name'] == 'MW1']
MW2 = IW[IW['Name'] == 'MW2']
MW3 = IW[IW['Name'] == 'MW3']
#initiate grid
xi = np.linspace(2517675,2517800,625)
yi = np.linspace(996300,996375,375)
#make it so i can apply np.float to an array
vector = np.vectorize(np.float)
X,Y = np.meshgrid(xi,yi)
#perform calculation over every X and Y.
PSI = ((MW1['Q']/(2*math.pi))*(np.arctan(((vector(X[None,:]))-np.float(MW1['X']))/(vector(Y[:,None])-np.float(MW1['Y']))))
(MW2['Q']/(2*math.pi))*(np.arctan(((vector(X[None,:])-np.float(MW2['X']))/vector((Y[:,None])-np.float(MW2['Y'])))))
(MW3['Q']/(2*math.pi))*(np.arctan(((vector((X[None,:])-np.float(MW3['X']))/vector((Y[:,None])-np.float(MW3['Y'])))))))
I get the error:
ValueError Traceback (most recent call last)
<ipython-input-11-fd6ee058014f> in <module>
17 X,Y = np.meshgrid(xi,yi)
18
---> 19 PSI = ((MW1['Q']/(2*math.pi))*(np.arctan(((vector(X[None,:]))-np.float(MW1['X']))/(vector(Y[:,None])-np.float(MW1['Y']))))
20 (MW2['Q']/(2*math.pi))*(np.arctan(((vector(X[None,:])-np.float(MW2['X']))/vector((Y[:,None])-np.float(MW2['Y'])))))
21 (MW3['Q']/(2*math.pi))*(np.arctan(((vector((X[None,:])-np.float(MW3['X']))/vector((Y[:,None])-np.float(MW3['Y'])))))))
~\Anaconda3\lib\site-packages\pandas\core\ops\common.py in new_method(self, other)
63 other = item_from_zerodim(other)
64
---> 65 return method(self, other)
66
67 return new_method
~\Anaconda3\lib\site-packages\pandas\core\ops\__init__.py in wrapper(left, right)
343 result = arithmetic_op(lvalues, rvalues, op)
344
--> 345 return left._construct_result(result, name=res_name)
346
347 wrapper.__name__ = op_name
~\Anaconda3\lib\site-packages\pandas\core\series.py in _construct_result(self, result, name)
2755 # We do not pass dtype to ensure that the Series constructor
2756 # does inference in the case where `result` has object-dtype.
-> 2757 out = self._constructor(result, index=self.index)
2758 out = out.__finalize__(self)
2759
~\Anaconda3\lib\site-packages\pandas\core\series.py in __init__(self, data, index, dtype, name, copy, fastpath)
311 try:
312 if len(index) != len(data):
--> 313 raise ValueError(
314 f"Length of passed values is {len(data)}, "
315 f"index implies {len(index)}."
ValueError: Length of passed values is 375, index implies 1.
I know that this has something to do with me trying to apply a function to an array that only accepts one value. I am trying to overcome this issue and be able to perform this calculation as is on the entire gridded data set. Any help on this would be greatly appreciated.
The equation i'm trying to do is below. Note that the theta in the equation is the arc tan of distance from the grid node to the injection well (for each grid node) which is what i'm trying to replicate in the code.
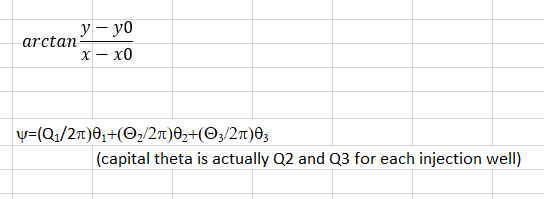
Thanks
CodePudding user response:
I'm gonna jump the gun here as I think I understand the problem now, after looking at it a bit more.
So you've got a DataFrame of injection well data, with four columns:
name x y q
str int int int
And you have a function f(x, y, q) -> z that you want to evaluate. I'm not sure I follow exactly what your function is doing because it's formatted in such a way that it's pretty hard to read, so I'll use a simplified example:
def func(x, y, q):
return (q / 2 * np.pi) * np.arctan(y, x)
Now instead of breaking your well data into different arrays, simply apply the function over the entire dataframe row-wise:
df["z"] = func(df.x, df.y, df.q)