I've a small project that is a little-bit head-breaking for me as not really a newbie in Python, i do some programming in Python for a few years in the weekend. But i see there are many ways to convert data in a csv file. I'm not sure which one to choose, and do not even really know where to start exactly, but i can do lot of research myself.
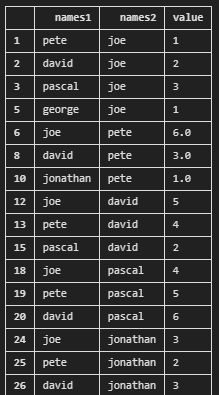
Now i have this dataset:
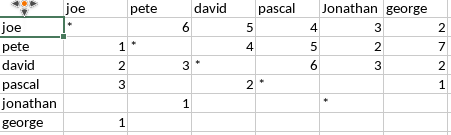
This is what i've got:
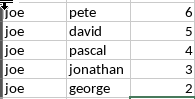
This is what i want:
Probably you guys know what module is the best for the given problem, currently I've my eyes on pandas and openpyxl.
Thx in advance!
CodePudding user response:
It doesn't have to be complicated. Given this program:
headings = []
for line in open('x.csv'):
parts = line.rstrip().split(',')
if not headings:
headings = parts
continue
for name,item in zip(headings, parts):
if item.isdigit():
print(','.join((parts[0], name, item)) )
This input:
x,joe,pete,david,pascal,jonathan,george
joe,*,6,5,4,3,2
pete,1,*,4,5,2,7
david,2,3,*,6,3,2
pascal,3,,2,*,,1
jonathan,,1,,,*,,
george,1,,,,,
Produces this output:
joe,pete,6
joe,david,5
joe,pascal,4
joe,jonathan,3
joe,george,2
pete,joe,1
pete,david,4
pete,pascal,5
pete,jonathan,2
pete,george,7
david,joe,2
david,pete,3
david,pascal,6
david,jonathan,3
david,george,2
pascal,joe,3
pascal,david,2
pascal,george,1
jonathan,pete,1
george,joe,1
CodePudding user response:
Depending on what you may want to do afterwards, a pandas option may be useful. In that case, you could simply use melt. Here, I have renamed the first column names1 but if it has another name, use that.
import pandas as pd
path = 'D:/'
file = 'data.csv'
data = pd.read_csv(path file, delimiter=',')
data = data.rename(columns={'Unnamed: 0':'names1'})
df = pd.melt(data, id_vars=['names1'], var_name='names2')
df = df.dropna(subset=['value'])
df = df[df['value'] != '*']