I'm trying to get the address in the 'From' column for the first-ever transaction for any token. Since there are new transactions so often thus making this table dynamic, I'd like to be able to fetch this info at any time using parsel selector. Here's my attempted approach:
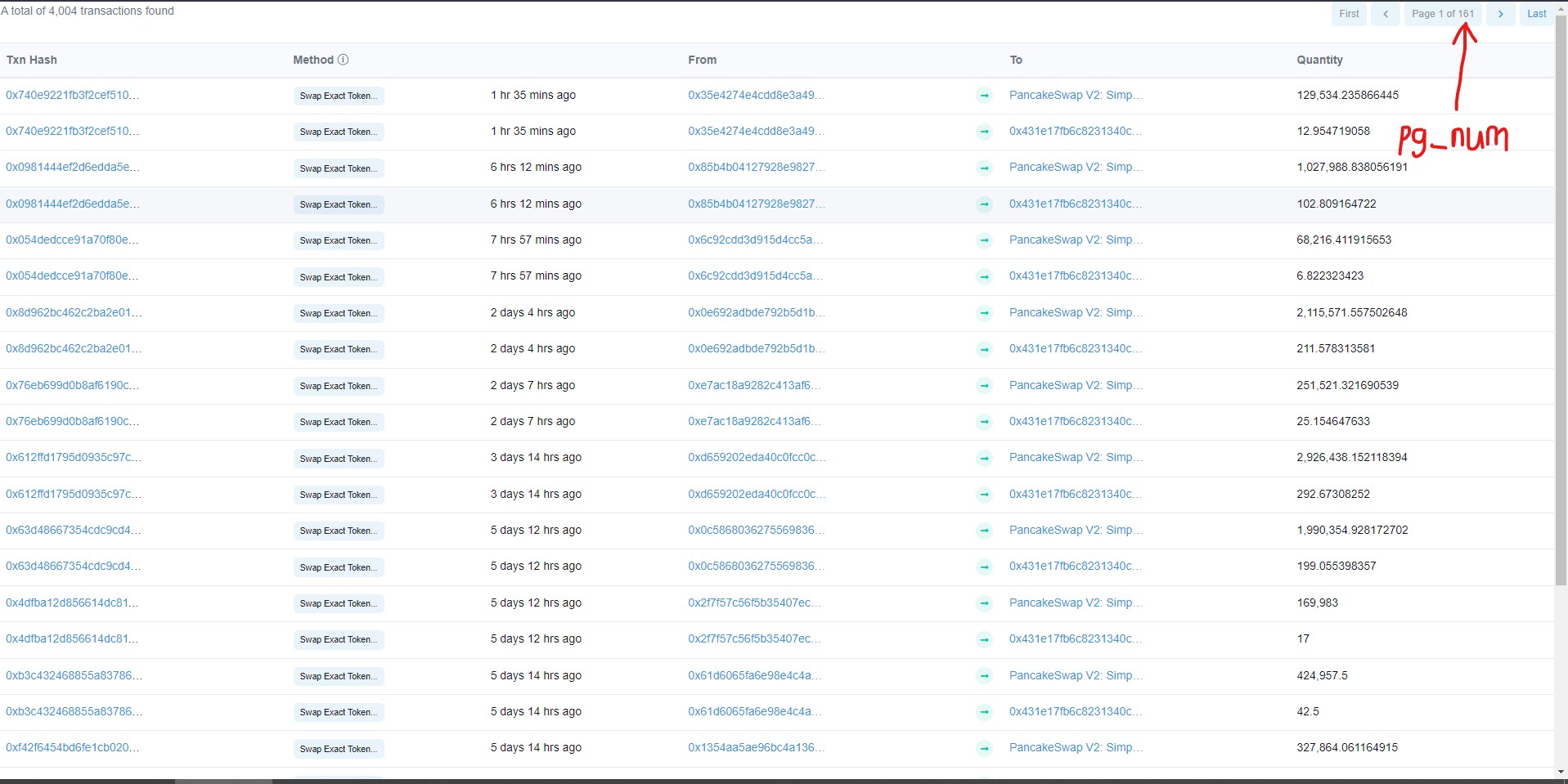
First step: Fetch the total number of pages
Second step: Insert that number into the URL to get to the earliest page number.
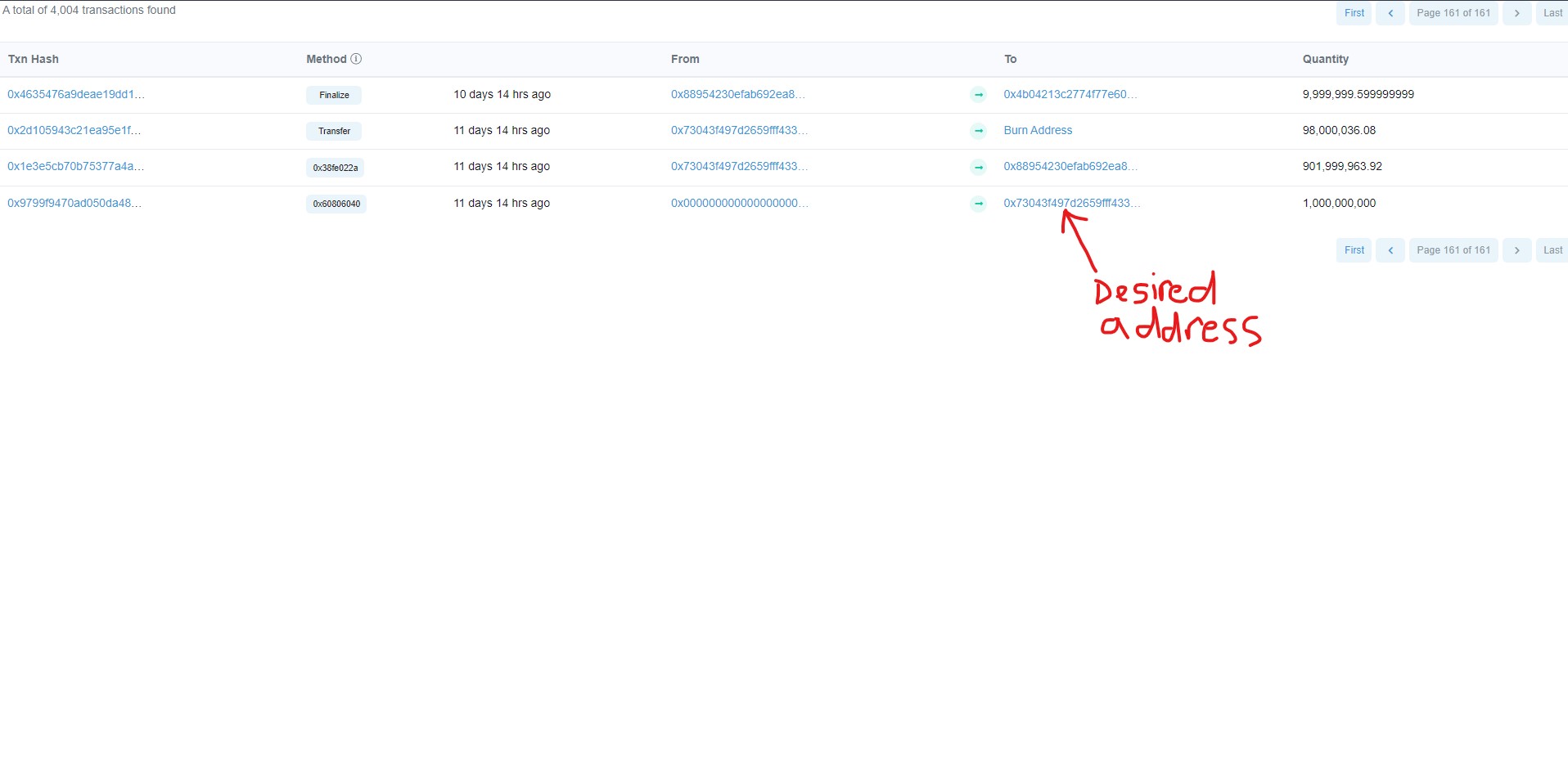
Third step: Loop through the 'From' column and extract the first address.
It returns an empty list. I can't figure out the source of the issue. Any advice will be greatly appreciated.
from parsel import Selector
contract_address = "0x431e17fb6c8231340ce4c91d623e5f6d38282936"
pg_num_url = f"https://bscscan.com/token/generic-tokentxns2?contractAddress={contract_address}&mode=&sid=066c697ef6a537ed95ccec0084a464ec&m=normal&p=1"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
response = requests.get(pg_num_url, headers=headers)
sel = Selector(response.text)
pg_num = sel.xpath('//nav/ul/li[3]/span/strong[2]').get() # Attempting to extract page number
url = f"https://bscscan.com/token/generic-tokentxns2?contractAddress={contract_address}&mode=&sid=066c697ef6a537ed95ccec0084a464ec&m=normal&p={pg_num}" # page number inserted
response = requests.get(url, headers=headers)
sel = Selector(response.text)
addresses = []
for row in sel.css('tr'):
addr = row.xpath('td[5]//a/@href').re('/token/([^#?] )')[0][45:]
addresses.append(addr)
print(addresses[-1]) # Desired address
CodePudding user response:
Seems like the website is using server side session tracking and a security token to make scraping a bit more difficult.
We can get around this by replicating their behaviour!
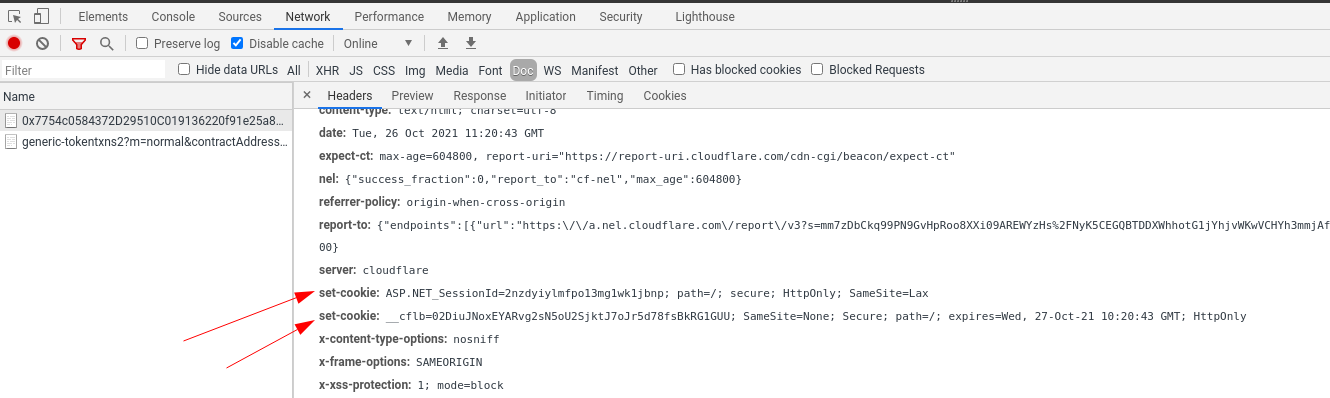
If you take a look at web inspector you can see that some cookies are being sent to us once we connect to the website for the first time:
Further when we click next page on one of the tables we see these cookies being sent back to the server:
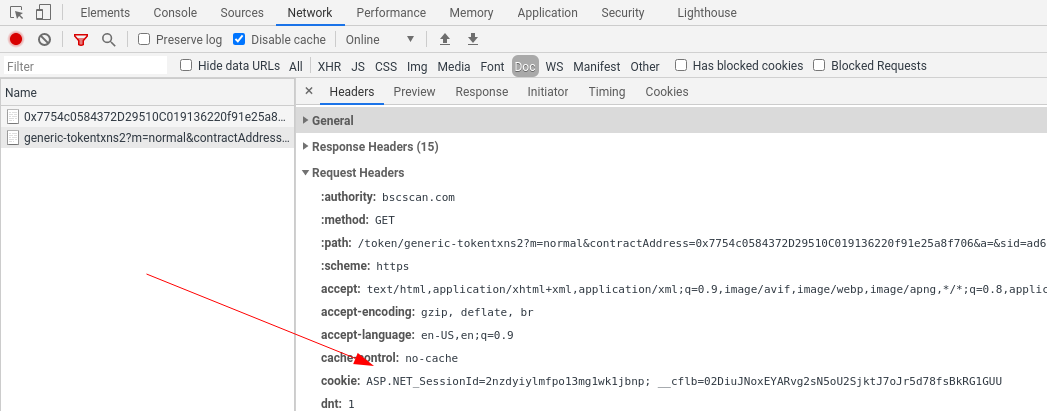
Finally the url of the table page contains something called sid this often stands for something like security id which can be found in 1st page body. If you inspect page source you can find it hidden away in javascript:
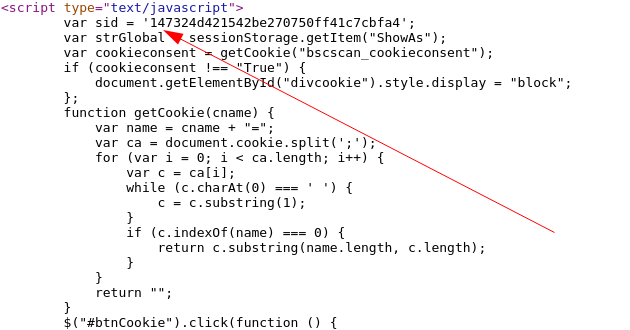
Now we need to put all of this together:
- start a requests
Sessionwhich will keep track of cookies - go to token homepage and receive cookies
- find
sidin token homepage - use cookies and
sidtoken to scrape the table pages
I've modified your code and it ends up looking something like this:
import re
import requests
from parsel import Selector
contract_address = "0x431e17fb6c8231340ce4c91d623e5f6d38282936"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
}
# we need to start a session to keep track of cookies
session = requests.session()
# first we make a request to homepage to pickup server-side session cookies
resp_homepage = session.get(
f"https://bscscan.com/token/{contract_address}", headers=headers
)
# in the homepage we also need to find security token that is hidden in html body
# we can do this with simple regex pattern:
security_id = re.findall("sid = '(. ?)'", resp_homepage.text)[0]
# once we have cookies and security token we can build the pagination url
pg_num_url = (
f"https://bscscan.com/token/generic-tokentxns2?"
f"contractAddress={contract_address}&mode=&sid={security_id}&m=normal&p=2"
)
# finally get the page response and scrape the data:
resp_pagination = session.get(pg_num_url, headers=headers)
addresses = []
for row in Selector(resp_pagination.text).css("tr"):
addr = row.xpath("td[5]//a/@href").get()
if addr:
addresses.append(addr)
print(addresses) # Desired address